Last week we had a large and highly-engaged audience at our live Webcast: “SMB 3.0 – New Opportunities for Windows Environments.” We ran out of time answering all the questions during our event so, as promised, here is a recap of all the questions and answers to attendees’ questions. The Webcast is now available on demand at http://snia.org/forums/esf/knowledge/webcasts. You can also download a copy of the presentation slides there.
Q. Have you tested SMB Direct over 40Gb Ethernet or using RDMA?
A. SMB Direct has been demonstrated using 40Gb Ethernet using TCP or RDMA and Infiniband using RDMA.
Q. 100 iops, really?
A. If you look at the bottom right of slide 27 (Performance Test Results) you will see that the vertical axis is IOPs/sec (Normalized). This is a common method for comparing alternative storage access methods on the same storage server. I think we could have done a better job in making this clear by labeling the vertical axis as “IOPs (Normalized).”
Q. How does SMB 3.0 weigh against NFS-4.1 (with pNFS)?
A. That’s a deep question that probably deserves a webcast of its own. SMB 3 doesn’t have anything like pNFS. However many Windows workloads don’t need the sophisticated distributed namespace that pNFS provides. If they do, the namespace is stitched together on the client using mounts and DFS-N.
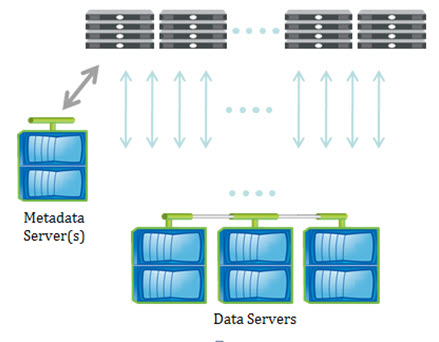
Q. In the iSCSI ODX case, how does server1 (source) know about the filesystem structure being stored on the LUN (server2) i.e. how does it know how to send the writes over to the LUN?
A. The SMB server (source) does not care about the filesystem structure on the LUN (destination). The token mechanism only loosely couples the two systems. They must agree that the client has permission to do the copy and then they perform the actual copy of a set of blocks. Metadata for the client’s file system representing the copied file on the LUN is part of the client workflow. Client drag/drops file from share to mounted LUN. Client subsystem determines that ODX is available. Client modifies file system metadata on the LUN as part of the copy operation including block maps. ODX is invoked and the servers are just moving blocks.
Q. Can ODX copies be within the same share or only between?
A. There is no restriction to ODX in this respect. The resource and destination of the copy can be on same shares, different shares, or even completely different protocols as illustrated in the presentation.
Q. Does SMB 3 provide API for integration with storage vendor snapshot other MS VSS?
A. Each storage vendor has to support Microsoft Remote VSS protocol, which is part of SMB 3.0 protocol specification. In Windows 2012 or Windows 8 the VSS APIs were extended to support UNC share path.
Q. How does SMB 3 compare to iSCSI rather than FC?
A. Please examine slide 27, which compares SMB 3, FC and iSCSI on the same storage server configuration.
Q. I have a question between SMB and CIFS. I know both are the protocols used for sharing. But why is CIFS adopted by most of the storage vendors? We are using CIFS shares on our NetApps, and I have seen that most of the other storage vendors are also using CIFS on their NAS devices.
A. There has been confusion between the terms “SMB” and “CIFS” ever since CIFS was introduced in the 90s. Fundamentally, the protocol that manages the data transfer between and client and server is SMB. Always has been. IMO CIFS was a marketing term created in response to Sun’s WebNFS. CIFS became popularized with most SMB server vendors calling their product a CIFS server. Usage is slowly changing but if you have a CIFS server it talks SMB.
Q. What is required on the client? Is this a driver with multi-path capability? Is this at the file system level in the client? What is needed in transport layer for the failover?
A. No special software or driver is required on the client side as long as it is running Windows 8 and later operating environment.
Q. Are all these new features cross-platform or is it something only supported by Windows?
A. SMB 3 implementations by different storage vendors will have some set of these features.
Q. Are virtual servers (cloud based) vs. non-virtual transition speeds greatly different?
A. The speed of a transition, i.e. failover is dependent on two steps. The first is the time needed to detect the failure and the second is the time needed to recover from that failure. While both a virtual and a physical server support transition the speed can significantly vary due to different network configurations. See more with next question.
Q. Is there latency as it fails over?
A. Traditionally SMB timeouts were associated with lower level, i.e. TCP timeouts. Client behavior has varied over the years but a rule-of-thumb was detection of a failure in 45 sec. This error would be passed up the stack to the user/application. With SMB 3 there is a new protocol called SMB Witness. A scale-out SMB server will include nodes providing SMB shares as well those providing Witness service. A client connects to SMB and Witness. If the node hosting the SMB share fails, the Witness node will notify the client indicating the new location for the SMB share. This can significantly reduce the time needed for detection. The scale-out SMB server can implement a proprietary mechanism to quickly detect node failure and trigger a Witness notification.
Q. Sync or Async?
A. Whether state movement between server nodes is sync or async depends on vendor implementation. Typically all updated state needs to be committed to stable storage before returning completion to the client.
Q. How fast is this transition with passing state id’s between hosts?
A. The time taken for the transition includes the time needed to detect the failure of Client A and the time needed to re-establish things using Client B. The time taken for both is highly dependent on the nature of the clustered app as well as the supported use case.
Q. We already have FC (using VMware), why drop down to SMB?
A. If you are using VMware with FC, then moving to SMB is not an option. VMware supports the use of NFS for hypervisor storage but not SMB.
Q. What are the top applications on SMB 3.0?
A. Hyper-V, MS-SQL, IIS
Q. How prevalent is true “multiprotocol sharing” taking place with common datasets being simultaneously accessed via SMB and NFS clients?
A. True “multiprotocol sharing” i.e. simultaneous access of a file by NFS & SMB clients is extremely rare. The NFS and SMB locking models don’t lend themselves to that. Sharing of a multiprotocol directory is an important use case. Users may want access to a common area from Linux, OS X and Windows. But this is sequential access by one OS/protocol at a time not all at once.
Q. Do we know growth % split between NFS and SMB?
A. There is no explicit industry tracker for the protocol split and probably not that much point in collecting them either, as the protocols aren’t really in competition. There is affinity among applications, OSes and protocols – MS products tend to SMB (Hyper-V, SQL Server,…), and non-Microsoft to NFS (VMware, Oracle, …). Cloud products at the point of consumption are normally HTTP RESTless protocols.