Storage traffic running over Ethernet-based networks has been around for as long as we have had Ethernet-based networks. Of course sometimes it is technically not accurate to think of the protocols as fundamentally Ethernet protocols – whilst FCoE, by definition, only runs on Ethernet, iSCSI, SMB, and NFS, they are, in reality, IP-based storage protocols and whilst most commonly run on Ethernet, could run on any network that supports IP. That notwithstanding, it is increasingly important to understand the real nature of Ethernet, and in particular, the nature of the new enhancements that we put under the umbrella of Data Center Bridging (DCB).
Although there is a great deal of information around DCB, there is also a lot of confusion where even the best articles miss describing a number of its elements. As such, with 10GbE ramping now is a good time to try to clarify the reality of what DCB does and does not do.
Perhaps the first and most important point is that DCB is, in reality, a task group in IEEE responsible for the development enhancements to the 802.1 bridge specifications that apply specifically to Ethernet Switching (or as IEEE say Bridging) in the datacenter. As such, DCB is not in itself a standard nor is the DCB group solely involved in those standards that apply to I/O and network convergence. The mots recent work of this task group falls into two distinct areas both of which apply to the datacenter one is the now completed standards around network and I/O convergence (802.1Qau,Qaz, Qbb) but the other are those standards that address the impact of server virtualization technology (802.1Qbg, BR, and the now withdrawn Qbh).

Also critical to understand, so that we do not overstate either the limitations of traditional Ethernet nor the advantages of the new standards around I/O and network convergence, is that these new standards build on top of many well understood, well used mature capabilities that already exist within the IEEE Ethernet standards set. Indeed IMHO, the most important element of this is that the DCB Convergence standards are building on top of the 802.1p capability to specify eight different classes of service through a 3-bit PCP field in the 802.1Q header the VLAN header. Or to say that in English Ethernet has for some considerable time had the ability to separate traffic into 8 separate categories to ensure that those different categories got different treatment – or more bluntly the fundamentals of I/O and network convergence are nothing new to Ethernet. Not only that, but the VLAN identification itself can be used to apply QoS on different sets of traffic, as does the fact that we can usually identify different traffic types by the Ethertype or IP socket.
So what is all the fuss about? As much as there were some good convergence capabilities, it was recognized that these could be further enhanced.
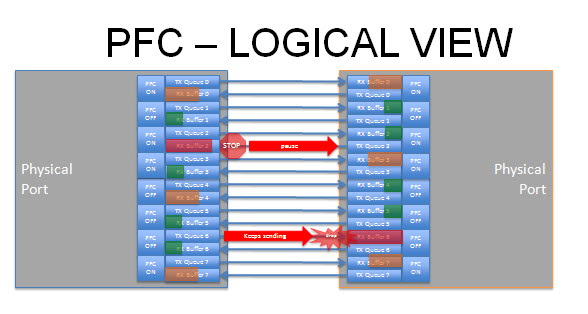
802.1Qbb or Priority-based Flow Control (PFC), far from adding into Ethernet a non-existent capability for lossless, simply takes the existing capability for lossless 802.3X and enhances it. 802.3X, when deployed with both RX and TX pause, can give lossless Ethernet as both recognized by many in the iSCSI community as well as by the FCoE specifications. However, the pause mechanisms apply at the port level, which means giving one traffic class lossless causes blocking of other traffic classes. All 802.1Qbb does, along with 802.3bd, is allow the pause mechanisms to be applied individually to specific priorities or traffic classes aka pause FCoE or iSCSI or RoCE whilst allowing other traffic to flow.
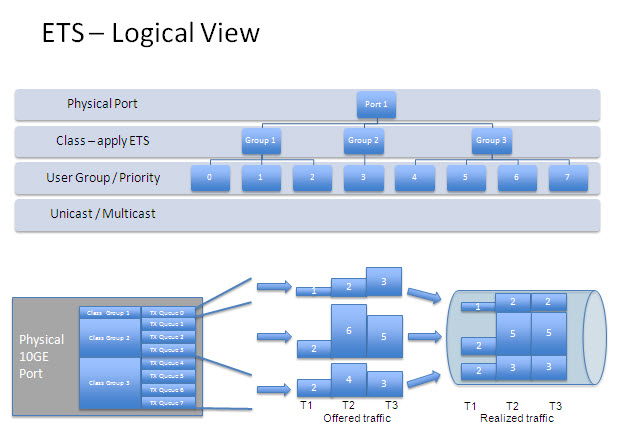
802.1Qaz or ETS (let’s ignore that DCBX is also part of this document and discussed in another SNIA-ESF blog) is not bandwidth allocation to your individual priorities, rather it is the ability to create a group of priorities and apply bandwidth rules to that group. In English, it adds a new tier to your QoS schedulers so you can now apply bandwidth rules to port, priority or class group, individual priority, and VLAN. The standard suggests a practice of at least three groups, one for best effort traffic classes, one for PFC-lossless classes, and one for strict priority though it does allow more groups.
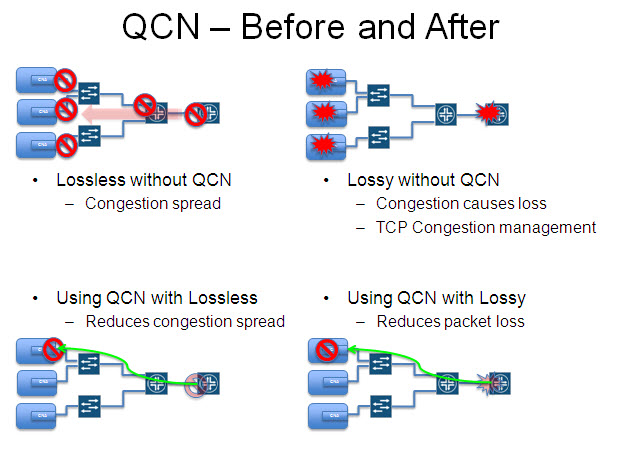
Last but not least, 802.1Qau or QCN is not a mechanism to provide lossless capabilities. Where pause and PFC are point-to-point flow control mechanisms QCN allows flow control to be applied by a message from the congestion point all the way back to the source. Being Ethernet level mechanisms it is of course across multiple hops within a layer 2 domain and so cannot cross either IP routing or FCF FCoE-based forwarding. If QCN is applied to a non PFC priority, then it would most likely reduce drop by telling the source device to slow down rather than having frames be dropped and allowing the TCP congestion window to trigger slowing down at the TCP level. If QCN is applied to a PFC priority, then it could reduce back propagation of PFC pause and so congestion propagation within that priority.
Although not part of the standards for DCB-based convergence, but mentioned in the standards, devices that implement DCB typically have some form of buffer carving or partitioning such that the different traffic classes are not just on different priorities or classes as they flow through the network, but are being queued in and utilizing separate buffer queues. This is important as the separated queuing and buffer allocation is another aspect of how fate sharing is limited or avoided between the different traffic classes. It also makes conversations around microbursts, burst absorption, and latency bubbles all far more complex than before when there was less or no buffer separation.
It is important to remember that what we are describing here are the layer 2 Ethernet mechanisms around I/O and network convergence, QoS, flow control. These are not the only tools available (or in operation) and any datacenter design needs to fully consider what is happening at every level of the network and server stack including, but not limited to, the TCP/IP layer, SCSI layer, and indeed application layer. The interactions between the layers are often very interesting but that is perhaps the subject for another blog.
In summary, with the set of enhanced convergence protocols now fully standardized and fairly commonly available on many platforms, along with the many capabilities that exist within Ethernet, and the increasing deployment of networks with 10GbE or above, more organizations are benefiting from convergence – but to do so they quickly find that they need to learn about aspects of Ethernet that in the past were perhaps of less interest in a non-converged world.