The SNIA Networking Storage Forum (NSF) kicked off the New Year with a live webcast “Virtualization and Storage Networking Best Practices.” We guessed it would be popular and boy, were we right! Nearly 1,000 people registered to attend. If you missed out, it’s available on-demand. You can also download a copy of the webcast slides.
Our experts, Jason Massae from VMware and Cody Hosterman from Pure Storage, did a great job sharing insights and lessons learned on best practices on configuration, troubleshooting and optimization. Here’s the blog we promised at the live event with answers to all the questions we received.
Q. What is a fan-in ratio?
A. fan-in ratio (sometimes also called an “oversubscription ratio”) refers to the number of hosts links related to the links to a storage device. Using a very simple example can help understand the principle:
Say you have a Fibre Channel network (the actual speed or protocol does not matter for our purposes here). You have 60 hosts, each with a 4GFC link, going through a series of switches, connected to a storage device, just like in the diagram below:

This is a 10:1 oversubscription ratio; the “fan-in” part refers to the number of host bandwidth in comparison to the target bandwidth.
Block storage protocols like Fibre Channel, FCoE, and iSCSI have much lower fan-in ratios than file storage protocols such as NFS, and deterministic storage protocols (like FC) have lower than non-deterministic (like iSCSI). The true arbiter of what the appropriate fan-in ratio is determined by the application. Highly transactional applications, such as databases, often require very low ratios.
Q. If there’s a mismatch in the MTU between server and switch will the highest MTU between the two get negotiated or else will a mismatch persist?
A. No, the lowest value will be used, but there’s a caveat to this. The switch and the network in the path(s) can have MTU set higher than the hosts, but the hosts cannot have a higher MTU than the network. For example, if your hosts are set to 1500 and all the network switches in the path are set to 9k, then the hosts will communicate over 1500.
However, what can, and usually does, happen is someone sets the host(s) or target(s) to 9k but never changes the rest of the network. When this happens, you end up with unreliable or even loss of connectivity. Take a look at the graphic below:
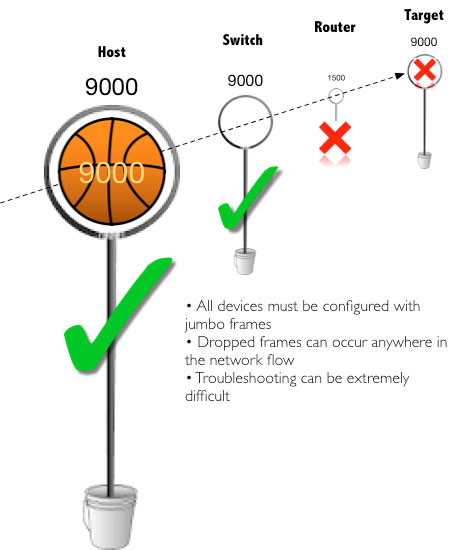
A large ball can’t fit through a hole smaller than itself. Consequently, a 9k frame cannot pass through a 1500 port. Unless you and your network admin both understand and use jumbo frames, there’s no reason to implement in your environment.
Q. Can you implement port binding when using two NICs for all traffic including iSCSI?
A. Yes you can use two NICs for all traffic including iSCSI, many organizations use this configuration. The key to this is making sure you have enough bandwidth to support all the traffic/ IO that will use those NICs. You should, at the very least, use 10Gb NICs faster if possible.
Remember, now all your management, VM and storage traffic are using the same network devices. If you don’t plan accordingly, everything can be impacted in your virtual environment. There are some hypervisors capable of granular network controls to manage which type of traffic uses which NIC, certain failover details and allow setting QoS limits on the different traffic types. Subsequently, you can ensure storage traffic gets the required bandwidth or priority in a dual NIC configuration.
Q. I’ve seen HBA drivers that by default set their queue depth to 128 but the target port only handles 512. So two HBAs would saturate one target port which is undesirable. Why don’t the HBA drivers ask what the depth should be at installation?
A. There are a couple of possible reasons for this. One is that many do not know what it even means, and are likely to make a poor decision (higher is better, right?!). So vendors tend to set these things at defaults and let people change them if needed—and usually that means they have purpose to change them. Furthermore, every storage array handles these things differently, and that can make it more difficult to size these things. It is usually better to provide consistency—having things set uniformly makes it easier to support and will give more consistent expectations even across storage platforms.
Second, many environments are large—which means people usually are not clicking and type through installation. Things are templatized, or sysprepped, or automated, etc. During or after the deployment their automation tools can configure things uniformly in accordance with their needs.
In short, it is like most things: give defaults to keep one-off installations simple (and decrease the risks from people who may not know exactly what they are doing), complete the installations without having to research a ton of settings that may not ultimately matter, and yet still provide experienced/advanced users, or automaters, ways to make changes.
Q. A number of white papers show the storage uplinks on different subnets. Is there a reason to have each link on its own subnet/VLAN or can they share a common segment?
A. One reason is to reduce the number of logical paths. Especially in iSCSI, the number of paths can easily exceed supported limits if every port can talk to every target. Using multiple subnets or VLANs can drop this in half—and all you really use is logical redundancy, which doesn’t really matter. Also, if everything is in the same subnet or VLAN and someone make some kind of catastrophic change to that subnet or VLAN (or some device in it causes other issues), it is less likely to affect both subnets/VLANs. This gives some management “oops” protection. One change will bring all storage connectivity down.
