More than 400 people have already seen our recent live ESF Webcast, “The Performance Impact of NVMe and NVMe over Fabrics.” If you missed it, it’s now available on-demand. It was a great session with a lot of questions from attendees. We did not have time to address them all – so here is a complete Q&A courtesy of our experts from Cisco, EMC and Intel. If you think of additional questions, please feel free to comment on this blog.
Q. Are you saying that just by changing the interface to NVMe for any SSD, one would greatly bump up the IOPS?
A. NVMe SSDs have higher IOPs than SAS or SATA SSDs due to several factors, including the low latency of PCIe and the efficiency of the NVMe protocol.
Q. How much of the speed of NVMe you have shown is due to simpler NVMe protocol vs. using Flash? i.e how would the SAS performance change when you are attaching SSD to SAS
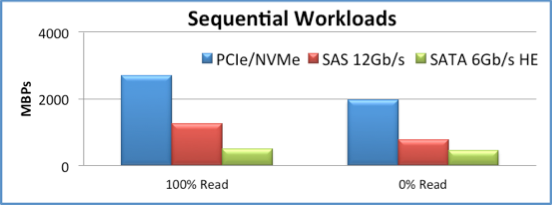
A. The performance differences shown comparing NVMe to SAS to SATA were all using solid-state drives (all NAND Flash). Thus, the difference shown was due to the interface.
Q. Can you comment on the test conditions these results were obtained under and what are the main reasons NVMe outperforms the others?
A. The most important reason NVMe outperforms other interfaces is that it was architected for NVM – rather than inheriting the legacy of HDDs. NVMe is built on the foundation of a very efficient multi-queue model and a simple hardware automatable command set that results in very low latency and high performance. Details for IOPs and bandwidth comparisons are shown in the footnotes of the corresponding foils. For the efficiency tests, the detailed setup information was inadvertantly removed from the backup. This will be corrected.
Q. What is the IOPS difference between NVMe and SAS at the same queue depth?
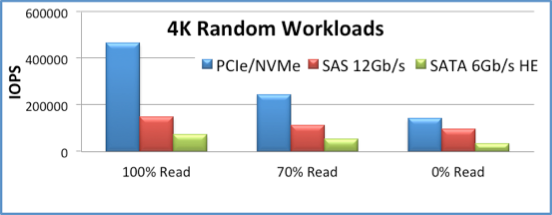
A. At a queue depth of 32, for the particular devices shown with 4K random reads is NVMe =~ 267K IOPs and SAS =~ 149K IOPs. SAS does not improve when the queue depth is increased to 128. NVMe performance increases to ~ 472K IOPs at a queue depth of 128.
Q. Why not use PCIe directly instead of the NVMe layer on PCIe?
A. PCI Express is used directly. NVM Express is the standard software interface for high performance PCI Express storage devices. PCI Express does not define register, DMA, command set, or feature set for PCIe storage devices. NVM Express replaces proprietary software interfaces and drivers used previously by PCIe SSDs in the market.
Q. Is the Working Group considering adding things like enclosure identification in the transport abstraction so the host/client can identify where the NVMe drives reside?
A. The NVM Express organization is developing a Management Interface specification set for release in Q1’2015 that will enable standardized enclosure management. The intent is that these features could be used regardless of fabric type (PCIe, RDMA, etc).
Q. Are there APIs in the software interface for device query information and device RAID configuration?
A. NVMe includes an Identify Controller and Identify Namespace command that provides information about the NVMe subsystem, controllers, and namespaces. It is possible to create a RAID controller that uses the NVMe interface if desired. Higher level software APIs are typically defined by the OSV.
Q. 1. Are NVMe drivers today multi-threaded? 2. If I were to buy a NVMe device today can you suggest some list of vendors whose solutions are used today in data centers (i.e production and not proof of concept or proto)?
A. The NVM Express drivers are designed for multi-threading – each I/O queue may be owned/controlled by one thread without synchronization with other driver threads. A list of devices that have passed NVMe interoperability and conformance testing are on the NVMe Integrator’s List.
Q. When do you think the market will consolidate for NVMe/PCIE based SSDs and End of SATA era ?
A. By 2018, IDC predicts that Enterprise SSDs by Interface will be PCIe=38%, SAS=28%, and SATA=34%. By 2018, Samsung predicts over 70% of client SSDs will be PCIe. Based on forecasts like this, we expect strong growth for NVMe as the standard PCIe SSD interface in both Enterprise and Client segments.
Q. why can’t it be like a graphic card which does memory transactions?
A. SSDs of today have much longer latency than memory – where a read from a typical NAND page takes > 50 microseconds. However, as next generation NVM comes to market over the next few years, there may be blurring of the lines between storage and memory, where next generation NVM may be used as very fast storage (like NVMe) or as memory as in NVDIMM type of usage models.
Q. It seems that most NVMe drive vendors supply proprietary drivers for their drives. What’s the value of NVMe over proprietary interfaces given this? Will we eventually converge on the open source driver?
A. As the NVMe ecosystem matures, we would expect most implementations would use inbox drivers that are present in many OSes, like Windows, Linux, and Solaris. However, in some Enterprise applications, a vendor may have a value added feature that could be delivered via their own software driver. OEMs and customers will decide whether to use inbox drivers or a vendor specific driver based on whether the value provided by the vendor is significant.
Q. To create an interconnect to a scale-out storage system with many NVMe drives does that mean you would you need an aggregated fabric link (with multiple RDMA links) to provide enough bandwidth for multiple NVMe drives?
A. Depends on the speed of the fabric links and the number of NVMe drives. Ideally, the target system would be configured such that the front-end fabric and back-end NVMe drives were bandwidth balanced. Scaling out multi-drive subsystems on a fabric may require the use of fat-tree switch topologies which may be constructed using some form of link aggregation. The performance of the PCIe NVMe drives is expected to put high bandwidth demands on the front-end network interconnect. Each NVMe SFF8639 2.5″ drive has a PCIe Gen3/x4 interconnect with the capability to product 3+ GB/s (24gbps) of sustained storage bandwidth. There are multiple production server systems with 4-8 NVMe sff8639 drive bays, which puts these platforms in the 200Gbps capability when used as NVMe over fabrics storage servers. The combination of PCIe NVMe drives and NVMe over fabric targets is going to have a significant impact on datacenter storage performance.
Q. In other forums we heard about NVMe extensions to deliver vendor specific value add features. Do we have any updates?
A. Each vendor is allowed to add their own vendor specific features and value. It would be best to discuss any vendor specific features with the appropriate vendor.
Q. Given that PCIe is not a scalable fabric at least from a storage perspective, do you see the need for SAS SSDs to increase or diminish over time? Or is your view that NVMe SSDs will populate the tier between DRAM and say, rotating media like SAS HDDs?
A. NVMe SSDs are the highest performance SSDs available today. If there is a box of NVMe SSDs, the most appropriate connection to that JBOD may may be Ethernet or another fabric that then fans out inside the JBOD to PCIe/NVMe SSDs.
Q. From a storage industry perspective, what deficiencies does NVMe have to displace SAS? Will that transition ever happen?
A. NVMe SSDs are seeing initial broad deployment primarily in server use cases that prize the high performance. Storage applications require a robust high availiability interface. NVMe has defined support for dual port, reservations, and other high availability features. NVMe will be used in storage applications as these high availability features mature in products.
Q. Will NVMe over fabrics allow to dma read/write the NVMe device directly (without going through system memory)?
A. The locality of the NVMe over Fabric buffers on the target-side are target implementation specific. That said, one could construct a target that used a 
pool of PCIe NVMe subsystem controller resident memory as the source and/or sink buffers of a fabric’s NIC’s NVMe data exchanges. This type of configuration will have the limitation of having to pre-determine fabric data to NVMe device locality else the data could end up in the wrong drive’s controller memory.
Q. Intel True scale fabric technology was based on Fulcrum ASIC. Could you please provide an input how Intel Omni Scale differs from Intel True Sclae fabric?
A. In the context of NVMe over Fabrics, Intel Omni-Path fabric is a possible future fabric candidate for an NVMe over Fabrics definition. Specifics on the fabric itself are outside of the scope of NVMe over Fabrics definition. For information on Omni-Path file, please refer to http://www.intel.com/content/www/us/en/omni-scale/intel-omni-scale-fabric-demo.html?wapkw=omni-scale.
Q. Can the host side NVMe client be in user mode since it is using RDMA?
A. It is possible since RDMA QP communications allow for both user and kernel mode access to the RDMA verbs. However, there are implications to consider. The NVMe host software currently resides in multiple operating systems as a kernel level block-storage driver. The goal is for NVMe over Fabrics to share common NVMe code between multiple fabric types in order to provide a consistent and sustainable core NVMe software. When NVMe over Fabrics is moved to user level, it essentially becomes a separate single-fabric software solution that must be maintained independently of the multi-fabric kernel NVMe software. There are some performance advantages of having a user-level interface, such as not having to go through the O/S system calls and the ability to poll the completions. These have to be weighed against the loss of kernel resident functionality, such as upper level kernel storage software, and the cost of sustaining the software.
Q. Which role will or could play the InfiniBand Protocol in the NVMe concept?
A. InfiniBandâ„¢ is one of the supported RDMA fabrics for NVMe over RDMA. NVMe over RDMA will support the family of RDMA fabrics through use of a common set of RDMA verbs. This will allow users to select the RDMA fabric type based on their fabric requirements and not be limited to any one RDMA fabric type for NVMe over RDMA.
Q. Where is this experimental code for NVMeOF for Driver and FIO available?
A. FIO is a common Linux storage benchmarking tool and is available from multiple Internet sites. The driver used in the demo was developed specifically as a proof of concept and demonstration for the Intel IDF 2014. They were based on a pre-standardized implementation of the NVMe over RDMA wire protocol. The standard NVMe over RDMA wire protocol is currently being under definition in NVM Express, Inc.. Once the standard is complete, both Host and reference Target drivers for Linux will be developed.
Q. Was polling on the completion queue used on the target side in the prototype?
A. The target side POC implementation used a polling technique for both the NVMe over RDMA CQ and NVMe CQ. This was to minimize the latency by eliminating the interrupt latency on the target for both CQs. Depending on the O/S and both the RDMA and NVMe devices interrupt moderation settings, interrupt latency is typically around 2 microseconds. If polling is not the desired model, Intel processors enable another form of event signaling called Monitor/Mwait where latency is typically in the 500ns latency range.
Q. In the prototype over iWARP, did the remote device dma write/read the NVMe device directly, or did it go through remote system memory?
A. In the PoC, all NVMe commands and command data went through the remote system memory. Only the NVMe commands were accessed by the CPU, the data was not touched.
Q. Are there any dependencies between NVMEoF using RDMA and iWARP? Can standard software RDMA in Linux distributions be used without need for iWARP support?
A. As mentioned, the NVMe over RDMA will be RDMA type agnostic and work with all RDMA providers that support a common set of RDMA verbs.
Q. PCIe doesn’t support multi-host access to devices. Does NVMe over fabric require movement away from PCIe?
A. The NVMe 1.1 specification specifically added features for multi-host support – allowing NVMe subsystems to have multiple NVMe controllers and multiple fabric ports. This model is supported in PCI Express by multi-function/ multi-port PCIe drives (typically referred to as dual-port). Dependng on the fabric type, NVMe over Fabrics will extend to configurations with many hosts sharing a single NVMe subsystem consisting of multiple NVMe controllers.
Q. In light of the fact that NVMe over Fabrics reintroduces more of the SCSI architecture, can you compare and contrast NVMe over Fabrics with ‘SCSI Express’ (SAM/SPC/SBC/SOP/PQI)?
A. NVMe over Fabrics is not a SCSI model, it’s extending the NVMe model onto other fabric types. The goal is to maintain the simplicity of the NVMe model, such as the small amount of NVMe command types, multi-queue interface model, and efficient NVM oriented host and controller implementations. We chose the RDMA fabric as the first fabric because it too was architected with a small number of operations, multi-queue interface model, and efficient low-latency operations.
Q. Is there an open source for NVMe over Fabrics, which was used for the IDF demo? If not, can that be made available to others to see how it was done?
A. Most of the techniques used in the PoC drivers will be implemented in future open-source Host and referent Target drivers. The PoC was both a learning and demonstration vehicle. Due to the PoC drivers using a pre-standards based NVMe over RDMA protocol, we feel it’s best not to propagate the implementation.
Q. What is the overhead of the protocol? Did you try putting NVMe in front just DRAM? I’d assume you’ll get much better results, and understand the limitations of the protocol much better. In front of DRAM it won’t be NVM, but it will give good data regarding protocol latency.
A. The overhead of the protocol on the host-side matched the PCIe NVMe driver. On the target, the POC protocol efficiency was around 600ns of compute latency for a complete 4K I/O. For low-latency media, such as DRAM or next generation NVM, the reduced latency of a solution similar to the PoC will enable the effective use of the media’s low latency characteristics.
Q. Do you have FC performance comparison with NVMe?
A. We did implement an 100GBE/FCoE target with NVMe back-end storage for an Intel IDF 2012 demonstration. FCoE is a combination of two models, FCP and SCSI. Our experience with this target implementation showed that we were adding a significant amount of computational latency on both the host (initiator) and target FCoE/FC/SCSI storage stacks that reduced the performance and efficiency advantages gained in the back-end PCIe NVMe SSDs. A significant component of this computational latency was due to the multiple storage models and associated translations that occurred between the host application and back-end NVMe drives This experience led us down the path of enabling an end-to-end NVMe model through expanding the NVMe model onto a range of fabric types.
Update: Want to learn more about NVMe? Check out these SNIA ESF webcasts: