More than 350 people have already seen our SNIA Ethernet Storage Forum (ESF) webcast “Clustered File Systems: No Limits.” Our presenters, James Coomer and Jerry Lotto, did a great job explaining what clustered file systems are, key considerations, choices and performance. As we expected, there were plenty of questions, so as promised, here are answers to them all.
Q: Parallel NFS (pNFS) has been in development/standard effort for a long time, and I believe pNFS is not in the Linux kernel it appears pNFS is yet to be prime time.
A: pNFS has been in Linux for over a decade! Clients and server are widely available, and you should look at the SNIA White Paper “An Updated Overview of NFSv4; NFSv4.0, NFSv4.1, pNFS, and NFSv4.2” for more information on the current state of play.
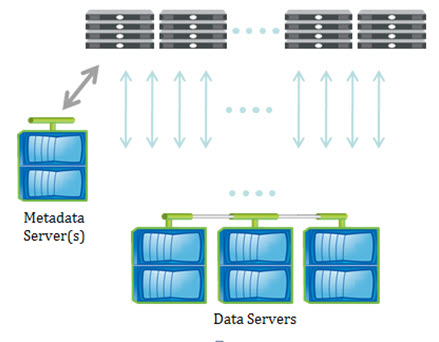
Q: Why the emphasis on parallel I/O? Any single storage server can feed results at link capacity, so you do not need multiple storage servers to feed a client at full speed. Isn’t the more critical issue the bottleneck on access to metadata for a single directory or file? Federated NAS bottlenecks updates for each directory behind a single master server?
A: Any one storage server can usually saturate one client, but often there are multiple hungry clients making requests simultaneously. Using parallel I/O allows multiple servers to feed multiple high-bandwidth clients across a narrow or wide set of data. This smooths out the I/O load on the servers in a near-perfect manner regardless of the number of clients performing I/O. It is absolutely true that metadata serving can become a bottleneck, so parallel file systems use cached and/or distributed metadata to overcome this and again, every client takes part in that interaction and shares some responsibility for managing communicating metadata updates.
Q: Can any application access parallel file system (i.e. through an agent in the driver level)? Or does it require specific code within the application?
A: Native access to a parallel file system requires a specific client or agent in the host, but many parallel file systems allow any client to access the data through a NAS protocol gateway. No changes are needed to applications to use a parallel file system – These parallel file systems are mounted as a POSIX compliant file system and therefore adhere to basically the same standards as an NFS mount for example.
Q: Are parallel file system clients compatible with scale-out NAS servers?
A: Nearly all scale-out NAS servers speak a standard NAS protocol like NFS or SMB. Clients running a parallel file system client can also access NAS via these standard protocols. Exceptions to this may possibly (but none that we know of) occur for scale-out NAS servers that support a modified NFS/SMB protocol or a custom NAS client which might conceivably conflict with the parallel file system client when installed on an OS.
Q: Of course I am biased, but I am fond of the AFS (Andrew File System) Family of File Systems. There is OpenAFS, but there is also what we are doing at AuriStor extending beyond the core AFS global namespace model (security functionality, and performance)
A: AFS is another distributed file system which supports large scale deployments, native clients for many platforms, and strong security features. It also uses local caching of files to improve performance. It uses a weakly consistent file locking system so multiple clients can access the same file simultaneously but they cannot both update the same file at the same time. OpenAFS is an open-source implementation of AFS. Auristor (formerly Your File System, Inc.) is a startup providing a commercial parallel file system that is compatible with AFS.
Q: I am more familiar with Veritas Cluster File System, could you please do a quick compare with Lustre or GPFS?
A: The Veritas Cluster File System (formerly VxCFS, now part of Veritas InfoScale) is a distributed file system that runs on Linux and popular flavors of Unix. It supports up to 64 nodes and allows multiple nodes to share the same back-end storage hardware. Comparing it to Lustre and GPFS is beyond the scope of this webinar, but in basic terms, parallel file systems can offer far greater scalability and bandwidth for example, through the use of optimized RDMA clients for high performance networks.
Q: Why do file apps need shared access to data, but block apps do not?
A: Traditionally block storage did not offer shared access to data (except when used as shared back-end storage for a clustered file system), while apps that needed shared access to data usually chose to use a NAS protocol such as SMB or NFS. So in many cases file-based apps use file sharing protocols because they need shared access to data from multiple clients. (In other cases file-based applications do not require sharing but the storage administrators believe it’s easier to manage or less expensive than networked block storage.)
Q: Do Lustre and GPFS have SMB Direct support?
A: Not today. SMB Direct is an option to use RDMA and multi-channel with the SMB 3 protocol. Both Lustre and GPFS support the ability to export a file system via NFS or SMB, but generally they do not support SMB Direct yet. Both Lustre and GPFS support RDMA access through their clients.
How to the clients avoid doing simultaneous writes to the same file?
A: Some parallel file systems allow this by letting different clients write to different parts of the same file. Others do not allow this. In either case, distributed file locking is used to prevent two clients from writing simultaneously to the same part of a file (or to the same file if it’s not allowed).
Q: How can you say that the application “does not have to worry about” how the clustered file system serializes writes? Doesn’t this require continuous end-to-end connectivity?
A: When the application writes data it generally writes to a POSIX-compliant file system and does not need to worry about how the parallel file system serializes, distributes, or protects the data because this is virtualized (managed) by the file system. It usually does require continuous end-to-end connectivity from the clients to the servers, though in some cases caching could allow for brief gaps in connectivity and in some systems not every client needs to have network connectivity to every server. There are multiple mechanisms within parallel file systems to manage the various cases of clients/servers disappearing from the network, temporarily or permanently (whilst for example holding a lock).
Q: How does a parallel file system handle the sequences of write on a same file? Just append one by one? What if a client modified a line?
A: This is the biggest challenge for and reason to use a parallel file system. Beneath the covers, coherency is maintained by Spectrum Scale using a token management server process which issues locks for object requests. Similar functionality is implemented in Lustre using a distributed lock manager. These objects are most commonly blocks within files rather than entire files, but this is application controlled. The end result is a POSIX-compliant interface that scales to thousands of clients.
Q: What does FPO stand for?
A: File Placement Optimizer – a shared-nothing architecture and licensing model for IBM Spectrum Scale (aka GPFS). Learn more here.
Q: Is there a concept in parallel file systems for “auto-tuning” yet? Seems like the early days of SAN management and tuning…
A: Default tuning values are optimized for general purpose workloads, but the whole purpose of tuning parameters is to adjust away from those defaults to optimize the file system for a particular application workload or fil esystem architecture. Both IBM and OpenSFS with the support of Intel have published extensive documentation on best practices for optimization and tuning for either file system. We are not aware of any work on “automating” that process but there has been recent work (e.g. in spectrum scale) to simplify the tuning process.
Q: Which is better as interconnect between disk and servers, shared access or share-nothing?
A: The use of shared access in the interconnect between disks and servers is limited to providing HA functionality in Lustre or Spectrum Scale, the ability to service I/O requests to a storage device if the server which has primary responsibility for that device is not available. This usually involves multiple server-attached external storage which can add cost to building the file system. The alternative approach to HA is to replicate blocks of data to different disks on different servers, cutting back on the usable capacity of the file system. If HA is not a requirement, a share-nothing architecture will generally involve less hardware and therefore be less expensive to build.
If you have more questions, please comment on this blog. And I encourage you to check out the SNIA ESF webcast library for educational, vendor-neutral content on Ethernet networked storage topics.
Update: If you missed the live event, it’s now available on-demand. You can also download the webcast slides.