Our VN2VN Webcast last week was extremely well received. The audience was big and highly engaged. Here is a summary of the questions attendees asked and answers from my colleague, Joe White, and me. If you missed the Webcast, it’s now available on demand.
Question #1:
We are an extremely large FC shop with well over 50K native FC ports. We are looking to bridge this to the FCoE environment for the future. What does VN2VN buy the larger company? Seems like SMB is a much better target for this.
Answer #1: It’s true that for large port count SAN deployments VN2VN is not the best choice but the split is not strictly along the SMB/large enterprise lines. Many enterprises have multiple smaller special purpose SANs or satellite sites with small SANs and VN2VN can be a good choice for those parts of a large enterprise. Also, VN2VN can be used in conjunction with VN2VF to provide high-performance local storage, as we described in the webcast.
Question #2: Are there products available today that incorporate VN2VN in switches and storage targets?
Answer #2: Yes. A major storage vendor announced support for VN2VN at Interop Las Vegas 2013. As for switches, any switch supporting Data Center Bridging (DCB) will work. Most, if not all, new datacenter switches support DCB today. Recommended also is support in the switch for FIP Snooping, which is also available today.
Question #3: If we have an iSNS kind of service for VN2VN, do you think VN2VN can scale beyond the current anticipated limit?
Answer #3: That is certainly possible. This sort of central service does not exist today for VN2VN and is not part of the T11 specifications so we are talking in principle here. If you follow SDN (Software Defined Networking) ideas and thinking then having each endpoint configured through interaction with a central service would allow for very large potential scaling. Now the size and bandwidth of the L2 (local Ethernet) domain may restrict you, but fabric and distributed switch implementations with large flat L2 can remove that limitation as well.
Question #4: Since VN2VN uses different FIP messages to do login, a unique FSB implementation must be provided to install ACLs. Have any switch vendors announced support for a VN2VN FSB?
Answer #4: Yes, VN2VN FIP Snooping bridges will exist. It only requires a small addition to the filet/ACL rules on the FSB Ethernet switch to cover VN2VN. Small software changes are needed to cover the slightly different information, but the same logic and interfaces within the switch can be used, and the way the ACLs are programmed are the same.
Question #5: Broadcasts are a classic limiter in Layer 2 Ethernet scalability. VN2VN control is very broadcast intensive, on the default or control plane VLAN. What is the scale of a data center (or at least data center fault containment domain) in which VN2VN would be reliably usable, even assuming an arbitrarily large number of data plane VLANs? Is there a way to isolate the control plane broadcast traffic on a hierarchy of VLANs as well?
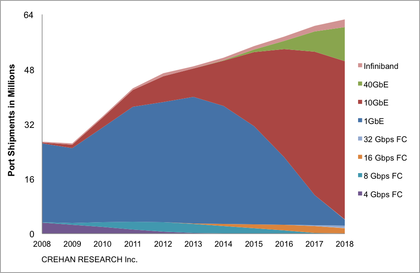
Answer #5: VLANs are an integral part of VN2VN within the T11 FC-BB-6 specification. You can configure the endpoints (servers and storage) to do all discovery on a particular VLAN or set of VLANs. You can use VLAN discovery for some endpoints (mostly envisioned as servers) to learn the VLANs on which to do discovery from other endpoints (mostly envisioned as storage). The use of VLANs in this manner will contain the FIP broadcasts to the FCoE dedicated VLANs. VN2VN is envisioned initially as enabling small to medium SANs of about a couple hundred ports although in principle the addressing combined with login controls allows for much larger scaling.
Question #6: Please explain difference between VN2VN and VN2VF
Answer #6: The currently deployed version of FCoE, T11 FC-BB-5, requires that every endpoint, or Enode in FC-speak, connect with the “fabric,” a Fibre Channel Forwarder (FCF) more specifically. That’s VN2VF. What FC-BB-6 adds is the capability for an endpoint to connect directly to other endpoints without an FCF between them. That’s VN2VN.
Question #7: In the context of VN2VN, do you think it places a stronger demand for QCN to be implemented by storage devices now that they are directly (logically) connected end-to-end?
Answer #7: The QCN story is the same for VN2VN, VN2VF, I/O consolidation using an NPIV FCoE-FC gateway, and even high-rate iSCSI. Once the discovery completes and sessions (FLOGI + PLOGI/PRLI) are setup, we are dealing with the inherent traffic pattern of the applications and storage.
Question #8: Your analogy that VN2VN is like private loop is interesting. But it does make VN2VN sound like a backward step – people stopped deploying AL tech years ago (for good reasons of scalability etc.). So isn’t this just a way for vendors to save development effort on writing a full FCF for FCoE switches?
Answer #8: This is a logical private loop with a lossless packet switched network for connectivity. The biggest issue in the past with private or public loop was sharing a single fiber across many devices. The bandwidth demands and latency demands were just too intense for loop to keep up. The idea of many devices addressed in a local manner was actually fairly attractive to some deployments.
Question #9: What is the sweet spot for VN2VN deployment, considering iSCSI allows direct initiator and target connections, and most networks are IP-enabled?
Answer #9: The sweet spot if VN2VN FCoE is SMB or dedicated SAN deployments where FC-like flow control and data flow are needed for up to a couple hundred ports. You could implement using iSCSI with PFC flow control but if TCP/IP is not needed due to PFC lossless priorities — why pay the TCP/IP processing overhead? In addition the FC encapsulation/serializaition and FC exchange protocols and models are preserved if this is important or useful to the applications. The configuration and operations of a local SAN using the two models is comparable.
Question #10: Has iSCSI become irrelevant?
Answer #10: Not at all. iSCSI serves a slightly different purpose from FCoE (including VN2VN). iSCSI allows connection across any IP network, and due to TCP/IP you have an end-to-end lossless in-order delivery of data. The drawback is that for high loss rates, burst drops, heavy congestion the TCP/IP performance will suffer due to congestion avoidance and retransmission timeouts (‘slow starts’). So the choice really depends on the data flow characteristics you are looking for and there is not a one size fits all answer.
Question #11: Where can I watch this Webcast?
Answer #11: The Webcast is available on demand on the SNIA website here.
Question #12: Can I get a copy of these slides?
Answer #12: Yes, the slides are available on the SNIA website here.