At our recent live ESF Webcast, “Expert Insights: Expanding the Data Center with FCoE,” we examined the current state of FCoE and looked at how this protocol can expand the agility of the data center if you missed it, it’s now available on-demand. We did not have time to address all the questions, so here are answers to them all. If you think of additional questions, please feel free to comment on this blog.
Q. You mentioned using 40 and 100G for inter-switch links. Are there use cases for end point (FCoE target and initiator) 40 and 100G connectivity?
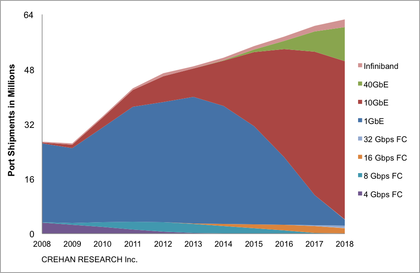
A. Today most end points are only supporting 10G, but we are starting to see 40G server offerings enter the market, and activity among the storage vendors designing these 40G products into their arrays.
Q. What about interoperability between FCoE switch vendors?
A. Each switch vendor has his own support matrix, and would need to be examined independently.
Q. Is FCoE supported on copper cable?
A. Yes, FCoE supports “Twin Ax” copper and is widely used for server to top of rack switch connections to seven meters. In fact, Converged Network Adapters are now available that support 10GBASE-T copper cables with the familiar RJ-45 jack. At least one major switch vendor has qualified FCoE running over 10GBASE-T to 30 meters.
Q. What distance does FCoE support?
A. Distance limits are dependent on the hardware in use and the buffering available for Priority Flow Control. The lengths can vary from 3m up to over 80km. Top of rack switches would fall into the 3m range while larger class switch/directors would support longer lengths.
Q. Can FCoE take part in management/orchestration by OpenStack Neutron?
A. As of this writing there are no OpenStack extensions in Neutron for FCoE-specific plugins.
Q. So how is this FC-BB-6 different than FIP snooping?
A. FIP Snooping is a part of FC-BB-5 (Appendix D), which allows switch devices to identify an FCoE Frame format and create a forwarding ACL to a known FCF. FC-BB-6 creates additional architectural elements for deployments, including a “switch-less” environment (VN2VN), and a distributed switch architecture with a controlling FCF. Each of these cases is independent from the other, and you would choose one instead of the others. You can learn more about VN2VN from our SNIA-ESF Webcast, “How VN2VN Will Help Accelerate Adoption of FCoE.”
Q. You mentioned DCB at the beginning of the presentation. Are there other purposes for DCB? Seems like a lot of change in the network to create a DCB environment for just FCoE. What are some of the other technologies that can take advantage of DCB?
A. First, DCB is becoming very ubiquitous. Unlike the early days of the standard, where only a few switches supported it, today most enterprise switches support DCB protocols. As far as other use cases for DCB, iSCSI benefits from DCB, since it eliminates dropped packets and the TCP/IP protocol’s backoff algorithm when packets are dropped, smoothing out response time for iSCSI traffic. There is a protocol known as RoCE or RDMA over Converged Ethernet. RoCE requires the lossless fabric DCB creates to achieve consistent low latency and high bandwidth. This is basically the InfiniBand API running over Ethernet. Microsoft’s latest version of file serving protocol, SMB Direct, and the Hyper-V Live Migration can utilize RoCE, and there is an extension to iSCSI known as iSER, which replaces TCP/IP with RDMA for the iSCSI datamover; enabling all iSCSI reads and writes to be done as RDMA operations using RoCE.
Q. Great point about RoCE. iSCSI RDMA (iSER) is required from DCB if the adapters support RoCE, right?
A. Agreed. Please see the answer above to the DCB question.
Q. Did that Boeing Aerospace diagram still have traditional FC links, and if yes, where?
A. There was no Fibre Channel storage attached in that environment. Having the green line in the ledger was simply to show that Fibre Channel would have it’s own color should there be any links.
Q. What is the price of a 10 Gbp CNA compare to a 10Gbps NIC ?
A. Price is dependent on vendor and economics. But, there are several approaches to delivering the value of FCoE which can influence pricing:
- Purpose built silicon that offloads the FC and Ethernet protocol functions offer a number of advantages including high performance, low CPU overhead, advanced features, etc., though even this depends on the vendor’s implementation. But, these added features come with the expectation of additional cost. But, the processing of the protocols has to be done somewhere, and if you need your server CPUs to process applications instead of network protocols, then the value is justified.
- With the introduction of Open FCoE drivers with DCB supported NICs, new options are available for customers to deploy the value of FCoE at the host. Open FCoE offloads the FC processing onto the host CPU and standard 10GbE NICs with DCB support can be used to manage the Ethernet transport functions. Where you have excess CPU capacity on your server, you might be in a position to reduce costs and deploy a software driver with a 10GbE or faster NIC enhanced with the limited set of hardware offloads necessary to achieve full performance with Open FCoE. However, Open FCoE isn’t available with every OS or every NIC, so you need to consider OS support and availability.
- A third consideration is that most enterprise servers include some form of advanced 10GbE networking on the motherboard that either supports purpose built silicon or DCB enabled silicon. So, depending upon which server and OS you deploy, you may have several options via embedded silicon.