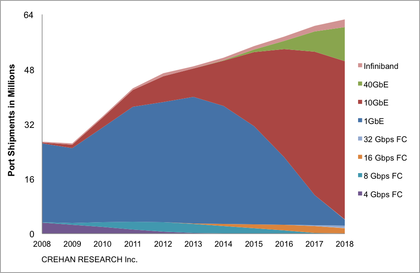
We had a tremendous response to our recent Webcast “Use Cases for iSCSI and FCoE – Where Each Makes Sense.” We had a lot of questions that we didn’t have time to address, so here are answers to them all. If you think of additional questions, please feel free to comment on this blog.
Q. You stated that FCoE requires End to End DCB connectivity. That is not entirely true if you have native Fibre Channel storage.
Once native FC is added, it is a hybrid FCoE/native FC network, not a simple FCoE network. To be clearer I could’ve stated that for FCoE all Ethernet links traversed must be DCB enabled.
Q. Any impact on the protocol choice if you bring SDN solutions with overlay networks using VXLAN or NVGRE within virtual switching in hypervisors into the picture?
An excellent question, but complicated enough that it probably deserves a discussion on its own. Overlay networks encapsulate Ethernet frames into routable packets. On a view of strict adherence to ISO ordering, that means L2 constructs like Data Center Bridging become “invisible” until decap. You lose the “lossless,” low-latency that FCoE expects and iSCSI may be taking advantage of, depending on your implementation. That doesn’t really favor one protocol over the other, but FCoE may lose advantages it has over iSCSI when confined to a single L2 subnet. But, unfortunately, the real answer to your question requires that you investigate in detail how the system software you are using handles encapsulated storage packets for both block storage protocols. Microsoft’s Hyper-V is different from VMware’s vSphere, and each flavor of SDN could be different as well. Proceed with caution.
Q. Have you heard of any enterprise customers who are interested in NIC Partitioning to separate iSCSI, FCoE, and typical network traffic? If so, can you provide information about those customers’ use cases?
We have not come across many customers that are interested in large-scale deployments yet.
Q. What are the use cases for using standalone FCoE switches in SAN keeping aside Cisco UCS and Blade Servers?
There are two ways to look at this:
1) To use FCoE as an end-to-end (Initiating server to target storage array) solution instead of, or to replace, Fibre Channel. Although, not very prevalent to date, the reason this option is chosen is to create a single converged LAN/SAN network that essentially retains the native FC constructs. The potential benefit would be in reduction in the amount of equipment required and the resources needed to deploy and administer two separate networks. This can be done in a phased approach, that uses multiprotocol switches, able to be used as Ethernet, FC or both on every port. This will provide future proofing, reduced qualification costs, and lower OPEX by no longer requiring the purchase of multiple switches of different protocols.
2) To continue the use of FC for connectivity from the Top of Rack switch to the storage arrays, but use FCoE connectivity for server access. This is much more prevalent, and even when deployed outside of the Cisco UCS blade servers, is used to increase flexibility in highly virtualized server environments or multi-tenancy, where workloads/VMs from the same physical servers need to connect to different storage types.
Q. How do iSCSI and FCoE switches handle redundancy? With FC, it is a best practice to implement dual fabrics with each storage system and server with paths down each.
Physical topology can be identical. A storage system has one set of targets (either IP addresses or FCoE targets) on one switch and other targets on the other switch. The initiators are configured to see any targets available on that leg.
To prevent Ethernet broadcast storms, technologies like per VLAN Spanning Tree and link aggregation are used. TRILL can also be used. For more details, I recommend reading this blog post by J Metz of Cisco. http://blogs.cisco.com/datacenter/understanding-fcoe-and-trill-the-easy-way/
Q. Doesn’t increasing CPU mean software processing for FCoE and iSCSI at both endpoints can reduce costs considerably (i.e. no full HBA functionality needed at the endpoints)?
Absolutely. If you have CPU cycles to spare at both endpoints, there is no reason to take on the extra cost of offload. However, remember the principle behind Moore’s law also works on things like network adapters and HBAs. It isn’t unreasonable to think that full offload capabilities will be included by default in a few years as technology progresses. And even if they aren’t, the actual application of Moore’s law will push the difference in CPU utilization to be trivial.
Q. How do large data centers configure and manage iSCSI? Is it by configuring the initiators and targets? My understanding is that most installations don’t use iSNS. Is this true?
It is true that most implementations of iSCSI don’t use iSNS. iSCSI initiators are simply configured with the target address by the administrator. In the FC world, SNS is simply there, but the iSCSI equivalent, iSNS, has always been optional. (SNS stands for Simple Name Service. It is a service that helps initiators find targets.)
Q. I have been doing a lot of testing to compare iSCSI to FC and noticed that as we move from traditional storage to SSD-based storage the IOPS increase faster for FCoE. For example, 18K+ for FCoE vs. 12K for iSCSI. Have you seen similar results?
I have seen some similar results. However, I’ve also seen some that don’t necessarily line up with that. I haven’t had the time to research this topic. Sounds like a good topic for a future post.
Q. Do you have any information about the number of customers who use FCoE Boot and iSCSI Boot?
Unfortunately I don’t. I do have anecdotal evidence to support customers using full-offload are more likely to boot from SAN. Since more full-offload FCoE adapters are in use that full-offload iSCSI adapters today, it makes sense that more are booting over FCoE than iSCSI, but again, I don’t have any evidence to support that.
Q. What about iSCSI over RoCE?
There are three network/fabric technologies that use RDMA: InfiniBand, iWARP, and RoCE. You can run iSCSI over any of these using the open-source iSER code supported by the Open Fabrics Alliance (https://www.openfabrics.org ). iSER has been written to OFA’s “verbs” for RDMA (rather than to the more familiar “sockets). However, note that of these three underlying transports, only iWARP is truly routable in general. So technically you could implement iSER on InfiniBand or RoCE but it may not do for you what you expect iSCSI to do for you, i.e., go anywhere the internet goes.
Q. How does FCIP compare with iSCSI for long distance requirements?
FC networks rely on guaranteed packet delivery to deliver low latency, predictable performance. IP networks are a best effort network allowing for dropped packets with transmission retries. Given the possibility of latency loss, FCIP has experienced limited adoption. Useful where required. But, typically not a core part of infrastructure. If cost is a concern and long distance is required as part of the solution, then iSCSI is the better choice as it designed to allow for lossy networks.
Q. Slide 22 – Was that hardware based iSCSI or software based iSCSI?
What was shown in the chart was software-based iSCSI, however you would see similar results with hardware-based iSCSI.
Q. What about FC vs FCoE performance? Any numbers?
Both Fibre Channel and FCoE can achieve line rate. Here’s an example of testing Yahoo! did on an 8Gb FC HBA and a 10 GbE CNA that showed exactly that result: http://www.intel.com/content/www/us/en/network-adapters/10-gigabit-network-adapters/10-gbe-ethernet-yahoo-case-study.html . So as Fibre Channel moves to 16 Gbps, it will outperform a 10GbE CNA, at least for peak performance. However, the tables turn with a 40 GbE CNA, several of which are in production now.
Q. Do you see SR-IOV used currently or in the future to separate FCoE or iSCSI from standard LAN traffic?
So far we have seen that with the exception of a few operating systems (e.g., AIX), SR-IOV support today is network only. Additionally, most customers want guaranteed bandwidth for storage and they wouldn’t be willing to run it on the same port as heavy NIC traffic.
Q. Are you aware of any FCoE targets for Windows?
I’m not aware of any right now.
Q. What is the max IOPS (at 4K) you can push thru 10G FCoE and iSCSI? Max latency (at 512 bytes)?
Latency is not determined by the pipe.
Q. Does FCoE really require a CNA? What about software only FCoE drivers?
Open FCoE does exist, but most FCoE implementations today use CNAs. I do expect the adoption of FCoE software solutions to increase fairly substantially. A lot of it comes down to the choice of booting via FCoE or another method.
Q. Do you think that the difference in FCoE/iSCSI usage for different App tiers can be related to the performance of the protocols?
Objectively, no. Either protocol implemented can be configured to hit or exceed a performance number. In my opinion, market perception of the protocols has more to do with the tier assignment than anything technical.
Q. Doesn’t 32 GbFC make it competitive with 40GbE FCoE?
From a purely technical perspective it helps, but FCoE is often deployed to reduce costs by simplifying cabling and switching by converging IP and storage onto the same fabric. 32Gb FC is slower than 40Gb and does nothing to reduce costs. Unless 32Gb FC is significantly less expensive than 40 Gb Ethernet on a per port basis, market forces are going to push towards Ethernet. There are still plenty of cases where organizations may deploy 32Gb FC instead of FCoE, but again, those criteria will mostly be non-technical.
Thanks to all my SNIA-ESF colleagues and Dell’Oro Group for helping me with these answers. If you missed the original Webcast, you can watch it on-demand here. You can also download a copy of the slides.