At our recent live ESF Webcast, “Object Storage 101,” we talked about the what, how, and why behind storage technologies. Over 200 people attended the event. If you missed it, it’s now available on-demand. It was an interactive session and we did not have time to address all the questions, so here are answers to them all. If you think of additional questions, please feel free to comment on this blog.
Q. Would Object Storage be a feasible solution for only the nearline storage tier?
Typically Yes. If we think about the latency needed for real-time transactions, these are best served using a cache storage tier such as NAND or large arrays of RAM. Object stores are excellent methods to store and retrieve large data sets within single/multiple containers. Note: most systems support offset reads so you don’t need to access an entire object to get to the section of interest.
Q. Where is the index to find the location of an object that is stored? Is it stored locally or stored distributedly or replicated among each clusters?
Storage of the Index or Metadata of objects that are stored, if used, typically is replicated throughout the system. Also, if the Metadata is lost, typically, these can be re-built as a maintenance function.
Q. How is the object stored/broken up? Aside from being stored by metadata (like name, size, etc) … what is the process of the fragmentation…breaking it up …as described during this erasure coding segment? Once it’s assigned some unique identifier … ie. an x-ray picture…. how is it addressed? (if not by block/bit/byte/level)?
Currently, Objects are stored using one of two methods of data protection either Replication or Erasure Coding. Some systems use both. That said, there are several algorithms used today to Erasure Code protect Objects. When using Reed-Solomon methods, you need to specify the number of “Data” Fragments and the number of the “Parity” fragments that will be created. The Size of each “Data” fragment is closely related to the Object size divided by the number of “Data” fragments requested. Each “Parity” fragment will be same size of each of the “Data” fragments created. The protected Object size is the sum of the “Data” fragments plus the “Parity” fragments created. Each of these fragments (Data and Parity) is stored on a different server for the purpose of avoiding a single point failure. The application that created the Object that will be accessing the Object store is responsible for keeping track of the ID of the Object and the Namespace the ID was stored in. Typically the Application will create an ID however, when an Application “Puts” an Object using an existing ID, the older stored Object using that same ID is overwritten. Typically, access into an Object Store using a RESTful Interface using commands like “Put, Get, Delete, List” over HTTP.
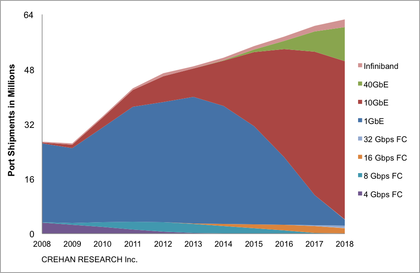
Q. Will Object storage drive network scale—further adoption of 10GE and 40GE or is 1GE enough?
Yes. If we think about the interconnection between the Control Plane and Data Plane of these systems (Orchestration and Object Storage Devices), better the connectivity the higher the performance.
Q. Is the number of fragments set or configurable? What are the trade-offs of requiring fewer fragments for recovery besides perhaps processing overhead? Are there any gotchas to watch out for/consider?
Yes. Storage policies are configurable. The number of “Parity” fragments defines the data loss risk. The more “Parity” fragments requested the lower this risk but this increases the storage resource needed for the Object. Eliminating single point failures is a key consideration. For example, if your Object Storage system has 10 servers, a storage policy using 9 of 12 will have 2 fragments of this Object located on 2 servers. In this case any single server failure would not cause data loss but may cause higher latency. However, if 3 servers would fail, you would lose access to your data until the servers were recovered. If the drives of the failed servers were not recovered then data loss would occur.
Q. Is erasure encoding used instead of Hash tagging?
No. Hash Tagging is a method of generating a unique number given a specific input of data, this number is used to find the location of the Object to be stored. Erasure Coding is the method used to create the fragments. So think of Hash tag as the seed to the address needed to find the fragments.
Q. How large are the fragments?
A rough estimate is the Object size divided by the number of fragments to re-hydrate the object. (e.g. 1GByte Object stored using a 8 of 12 policy would have a fragment size of 1GByte/8 =~ 125MByte
Q. What do you see as the requirement for the interconnect between the Object storage arrays/boxes to be? Very large pipes as in multiple 40G links or something lower?
It depends on the use case or Service Level Objective for the system. If your system design uses a Proxy service and Erasure Coding, then your back end network throughput (the network connecting the Proxy and Object Storage Devices – Storage Servers) will aggregated (Multiply). In this case the network throughput is based on the number of “Data” fragments being used. If you use Replication, then the back end network throughput will not aggregate. This multiplication factor, if present, is key to an efficient network strategy. In Non-Proxy based Object Storage designs or replication based Object Storage systems the network strategy will scale with network bandwidth to the limitation of the HDDs ability to server data.
Q. What about access control and security at the object level? Is that typically part of the model?
Typically, access control methods are at the gateway or entry point of a Namespace. The access method used is up to the vendor of the Object Store.
Q. What is the presentation mode at the host level? i.e. a drive mapping or similar
Typically presentation methods are a RESTful API via HTTP. This used “PUT, GET, DELETE, LIST” semantics.
Q. Can you explain the differences/similarities between object storage, CDMI and software defined storage?
Object Stooge defined a system (Software + Hardware) to storage Objects. CDMI defends a method used to access/connect your application to an Object Storage system. Software Defined Storage describes using standard high volume servers with software for the purpose of storing data.
Q. Why can’t a traditional approach be used to Object Storage for its durability?
Traditional storage approaches such as direct attached storage (RAID Sets) do not scale. Once you run out of space, managing additional storage on separate systems becomes the issue.
Q. Aren’t all types of data going to need the accessibility required by users? For example, isn’t everything going to need to placed in an object store?
There is a lot of debate on this issue. The goal of an Object Store is two fold. 1) Drive down the cost/Byte and 2) keep content readily accessible.
Q. How to we avoid losing the Metadata from the data? Also, is there something like sub-meta data, where a small amount of Metadata is contained within the data and the larger Metadata is stored somewhere else?
Some Object storage systems support Extended File Attributes, which is a file system feature that allows the Applications to store “Metadata” about an Object which is then bound to the Object within the storage environment. These Extended File Attributes (XATTR’s) can be queried separately and can be used by your application as you see fit. The management of the XATTR’s is handled by the local file system and accessed by the Object Storage software via the RESTful API using HTTP.
Q. Is maintaining multiple copies mainly for durability or can it be used for performance enhancement (parallel access), or is that irrelevant?
Absolutely! Management of copies/replicas can serve multiple purposes. Replication across racks, datacenters, geographies, etc. can provide resiliency against failures at those levels. Replication can also be used to provide object access in close proximity to the requester. In the X-ray example discussed in the Webcast, we might set up a replica local to the medical practice for the first 90 days, in order to provide a low latency (time to first byte) copy during the initial treatment. Additional copies can be kept at remote sites in order to provide fault tolerance.
Q. Is there a standard methodology for migrating from a file-system based methodology to an object store?
The short answer is no. In general an application that is currently developed to use file or block based storage will need to be re-architected in order to take advantage of an object storage system/service. There is, however, a growing category of products referred to as “cloud gateways” that can provide a bridge to object storage by presenting a filesystem to the existing application, while writing and reading via a RESTful API to a backend object storage system/service.
Q. Is it safe to say that in order to use object storage the application needs to be “object storage aware”? Unlike a traditional storage where the application doesn’t necessarily need to be familiar with the storage or file system since that is handled at a lower layer.
Yes, however as indicated in the question regarding migration of applications above, it is possible to implement a “cloud gateway” solution that will provide the translation from RESTful API to a CIFS/NFS fileshare, thus not requiring any application changes. I would disagree with the premise that traditional applications don’t need to be familiar with the underlying storage. Traditional file-based applications must understand the location (fileserver, folder, filename, etc.) in order to gain access to the appropriate data.
Q. I’m hearing a lot of ‘what’ and ‘how’ but not so much ‘why’ about object storage. Can we hear some real-world examples of applications in industry today that are running better because of object storage?
An example of an application running today with object storage behind it, and why: Web Based Media Asset Management/Distribution. This particular use case tends to deal with billions of files/objects that can vary in size from very small thumbnail images to massive 4k HD movie files. The ability to deliver these to multiple platforms (phone, laptop, set top box, etc.) across multiple geographies is something that is well suited for object storage. Traditional file and/or block based storage environments may hit scale limitations in dealing with the number of files/objects, in addition the ability to have a single namespace maintained across multiple locations/datacenters is something that is exceedingly complex for storage environments other than object stores.
Q. Replicating an object two or three times would exponentially increase storage costs, wouldn’t it? The more copies the higher the costs?
Certainly more copies would use more storage, and as a result most object stores provide different durability schemes based upon the performance/availability tradeoffs the data owner is willing to make. Recovering a single object from a replica is significantly faster than rebuilding an object from geo-distributed EC fragments. Also, as discussed in the question above related to replicas to drive performance, replication can serve the purpose of placing objects as close to the consumer as possible, minimizing time to first bye and increasing the overall throughput of an application.
Q. If I have an app that access a CIFS share, is there a way to translate it into object store?
Please see answer to question: “Is there a standard methodology for migrating from a file-system based methodology to an object store?” Short answer: Yes, via a “cloud gateway” product.
Q. Is there a confluence point of Object and File based storage – specifically in NAS where object storage can be multi-protocol (NFS, and REST)?
While there are some object storage solutions that provide their own native cloud-gateway capability (NAS protocol to the application, RESTful API to the object store). There are very few that provide a “file/object duality” capability allowing applications to manipulate an object as both an object and a file.