In this third and final blog post on NFS (see previous blog posts Why NFSv4.1 and pNFS are Better than NFSv3 Could Ever Be and The Advantages of NFSv4.1) I’ll cover pNFS (parallel NFS), an optional feature of NFSv4.1 that improves the bandwidth available for NFS protocol access, and some of the proposed features of NFSv4.2 – some of which are already implemented in commercially available servers, but will be standardized with the ratification of NFSv4.2 (for details, see the IETF NFSv4.2 draft documents).
Finally, I’ll point out where you can get NFSv4.1 clients with support for pNFS today.
Parallel NFS (pNFS) and Layouts
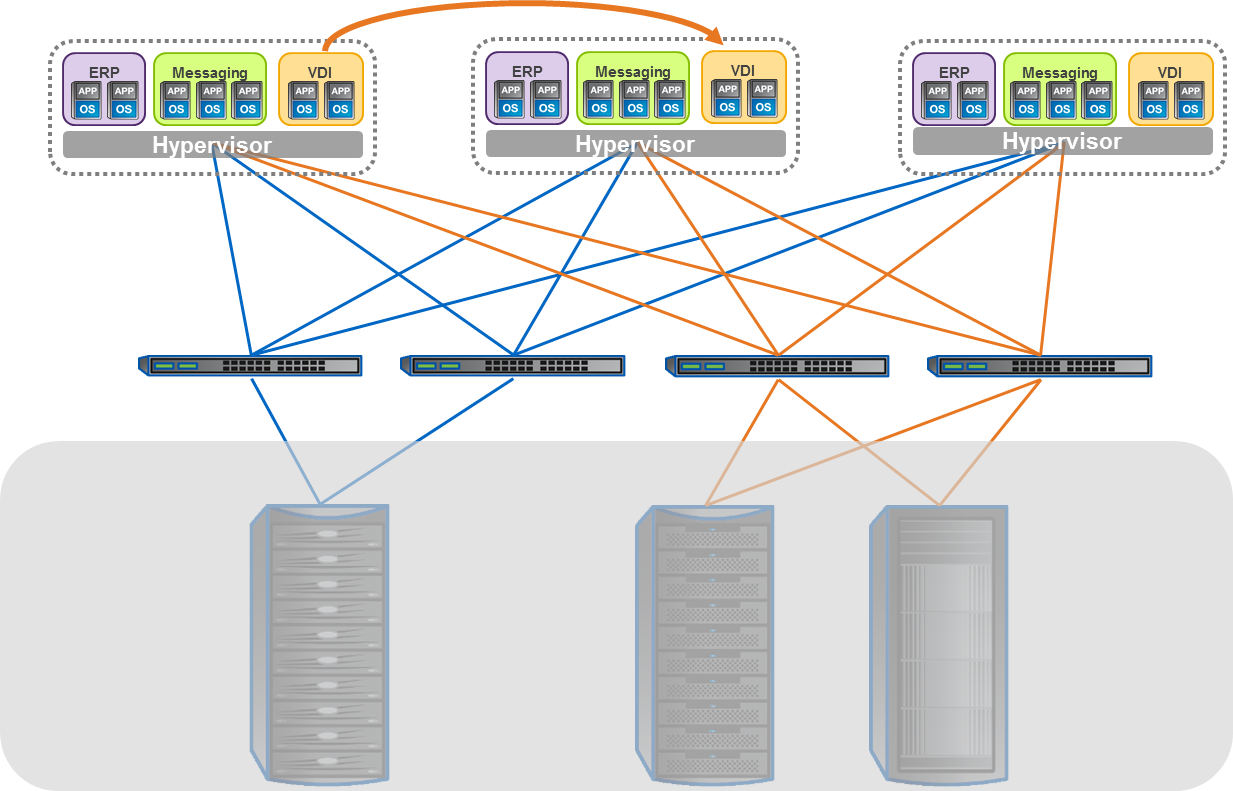
Parallel NFS (pNFS) represents a major step forward in the development of NFS. Ratified in January 2010 and described in RFC-5661, pNFS depends on the NFS client understanding how a clustered filesystem stripes and manages data. It’s not an attribute of the data, but an arrangement between the server and the client, so data can still be accessed via non-pNFS and other file access protocols. pNFS benefits workloads with many small files, or very large files, especially those run on compute clusters requiring simultaneous, parallel access to data.
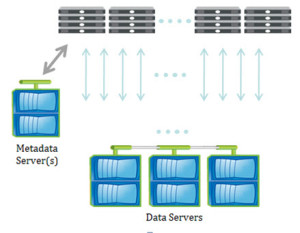
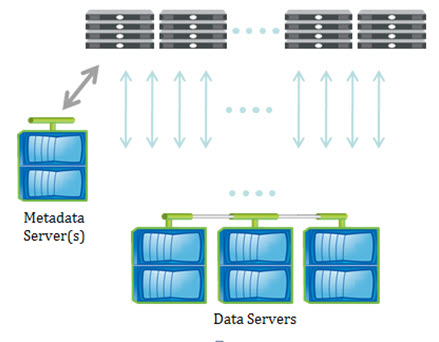
Clients request information about data layout from a Metadata Server (MDS), and get returned layouts that describe the location of the data. (Although often shown as separate, the MDS may or may not be standalone nodes in the storage system depending on a particular storage vendor’s hardware architecture.) The data may be on many data servers, and is accessed directly by the client over multiple paths. Layouts can be recalled by the server, as in the case for delegations, if there are multiple conflicting client requests.
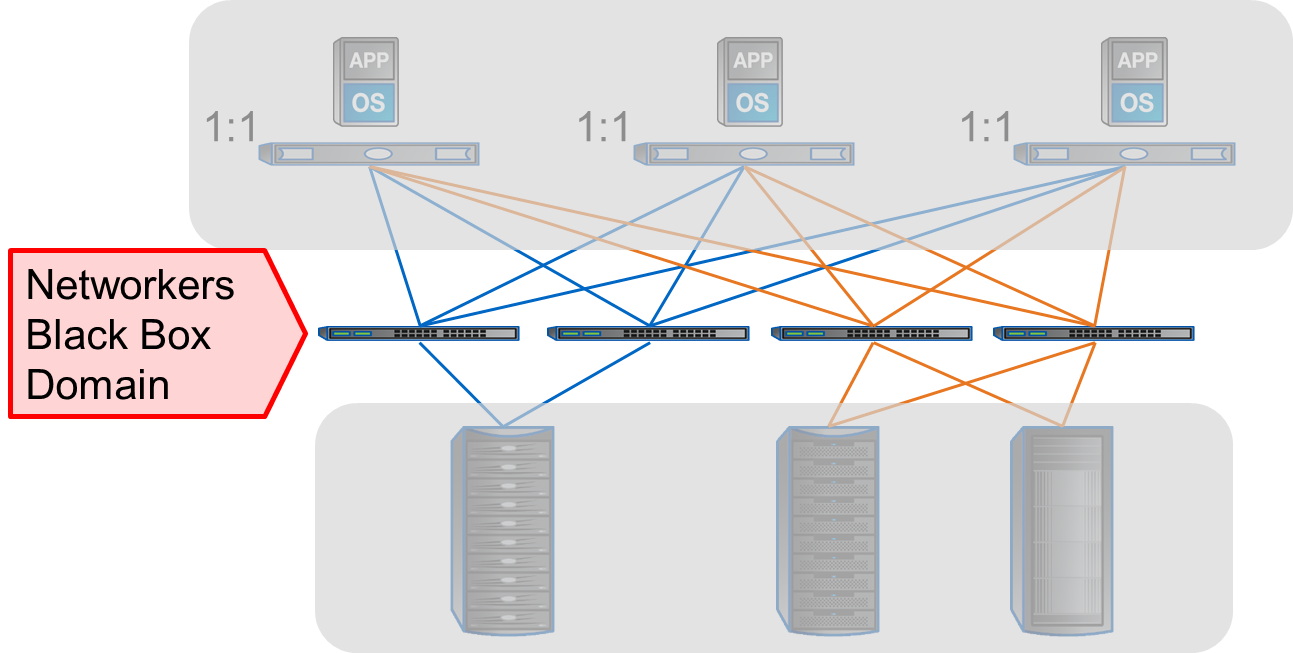
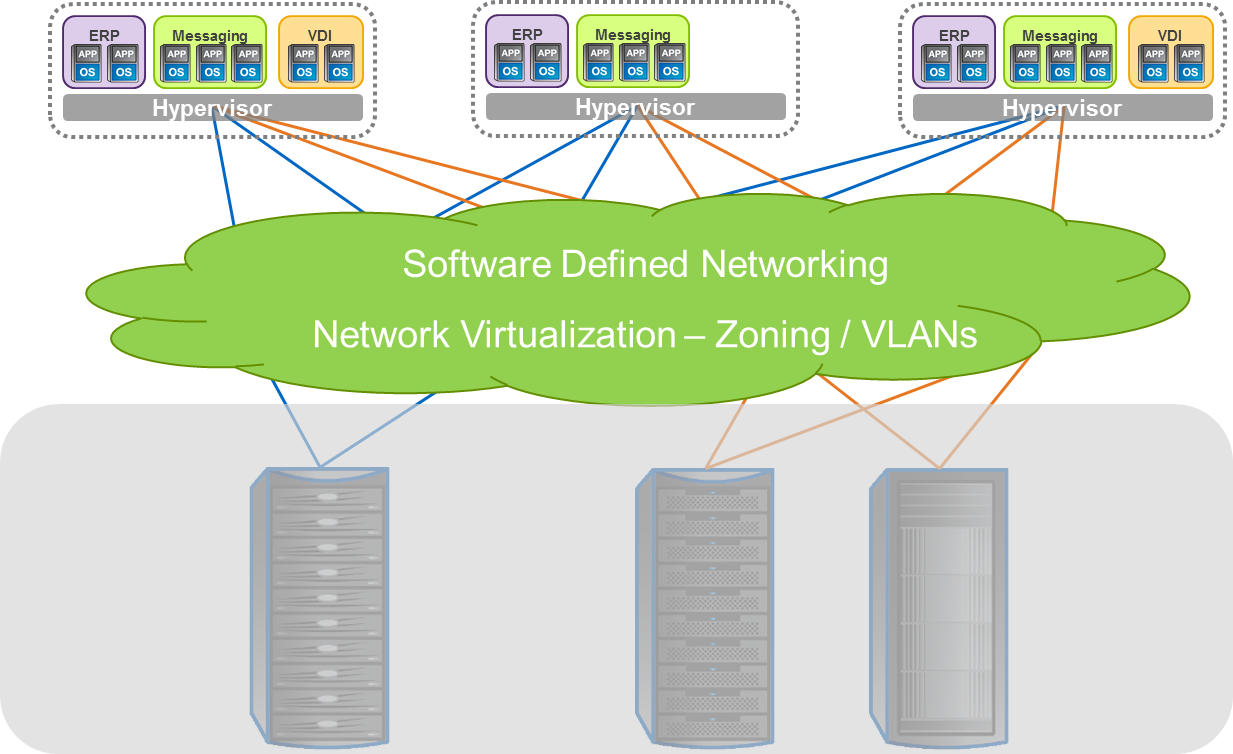
By allowing the aggregation of bandwidth, pNFS relieves performance issues that are associated with point-to-point connections. With pNFS, clients access data servers directly and in parallel, ensuring that no single storage node is a bottleneck. pNFS also ensures that data can be better load balanced to meet the needs of the client.
The pNFS specification also accommodates support for multiple layouts, defining the protocol used between clients and data servers. Currently, three layouts are specified; files as supported by NFSv4, objects based on the Object-based Storage Device Commands (OSD) standard (INCITS T10) approved in 2004, and block layouts (either FC or iSCSI access). The layout choice in any given architecture is expected to make a difference in performance and functionality. For example, pNFS object based implementations may perform RAID parity calculations in software on the client, to allow RAID performance to scale with the number of clients and to ensure end-to-end data integrity across the network to the data servers.
So although pNFS is new to the NFS standard, the experience of users with proprietary precursor protocols to pNFS shows that high bandwidth access to data with pNFS will be of considerable benefit.
Potential performance of pNFS is definitely superior to that of NFSv3 for similar configurations of storage, network and server. The management is definitely easier, as NFSv3 automounter maps and hand-created load balancing schemes are eliminated; and by providing a standardized interface, pNFS ensures fewer issues in supporting multi-vendor NFS server environments.
Some Proposed NFSv4.2 features
NFSv4.2 promises many features that end-users have been requesting, and that makes NFS more relevant as not only an “every day” protocol, but one that has application beyond the data center. As the requirements document for NFSv4.2 puts it, there are requirements for:
- High efficiency and utilization of resources such as, capacity, network bandwidth, and processors.
- Solid state flash storage which promises faster throughput and lower latency than magnetic disk drives and lower cost than dynamic random access memory.
Server Side Copy
Server-Side Copy (SSC) removes one leg of a copy operation. Instead of reading entire files or even directories of files from one server through the client, and then writing them out to another, SSC permits the destination server to communicate directly to the source server without client involvement, and removes the limitations on server to client bandwidth and the possible congestion it may cause.
Application Data Blocks (ADB)
ADB allows definition of the format of a file; for example, a VM image or a database. This feature will allow initialization of data stores; a single operation from the client can create a 300GB database or a VM image on the server.
Guaranteed Space Reservation & Hole Punching
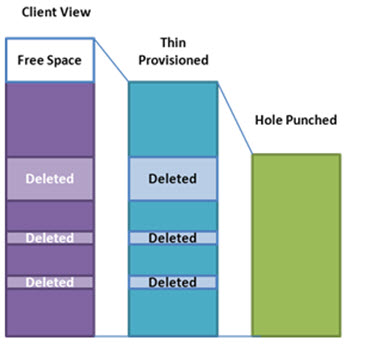
As storage demands continue to increase, various efficiency techniques can be employed to give the appearance of a large virtual pool of storage on a much smaller storage system. Thin provisioning, (where space appears available and reserved, but is not committed) is commonplace, but often problematic to manage in fast growing environments. The guaranteed space reservation feature in NFSv4.2 will ensure that, regardless of the thin provisioning policies, individual files will always have space available for their maximum extent.
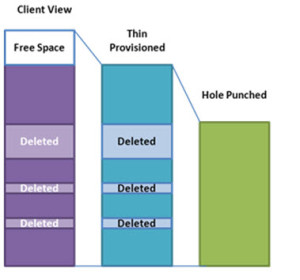
While such guarantees are a reassurance for the end-user, they don’t help the storage administrator in his or her desire to fully utilize all his available storage. In support of better storage efficiencies, NFSv4.2 will introduce support for sparse files. Commonly called “hole punching”, deleted and unused parts of files are returned to the storage system’s free space pool.
Obtaining Servers and Clients
With this background on the features of NFS, there is considerable interest in the end-user community for NFSv4.1 support from both servers and clients. Many Network Attached Storage (NAS) vendors now support NFSv4, and in the last 12 months, there has been a flurry of activity and many developments in server support of NFSv4.1 and pNFS.
For NFS server vendors, there are NFSv4.1 and files based, block based and object based implementations of pNFS available; refer to the vendor websites, where you will get the latest up-to-date information.
On the client side, there is RedHat Enterprise Linux 6.4 that includes full support for NFSv4.1 and pNFS (see www.redhat.com), Novell SUSE Linux Enterprise Server 11 SP2 with NFSv4.1 and pNFS based on the 3.0 Linux kernel (see www.suse.com), and Fedora available at fedoraproject.org.
Conclusion
NFSv4.1 includes features intended to enable its use in global wide area networks (WANs). These advantages include:
- Firewall-friendly single port operations
- Advanced and aggressive cache management features
- Internationalization support
- Replication and migration facilities
- Optional cryptography quality security, with access control facilities that are compatible across UNIX ® and Windows ®
- Support for parallelism and data striping
The goal for NFSv4.1 and beyond is to define how you get to storage, not what your storage looks like. That has meant inevitable changes. Unlike earlier versions of NFS, the NFSv4 protocol integrates file locking, strong security, operation coalescing, and delegation capabilities to enhance client performance for data sharing applications on high-bandwidth networks.
NFSv4.1 servers and clients provide even more functionality such as wide striping of data to enhance performance. NFSv4.2 and beyond promise further enhancements to the standard that increase its applicability to today’s application requirements. It is due to be ratified in August 2012, and we can expect to see server and client implementations that provide NFSv4.2 features soon after this; in some cases, the features are already being shipped now as vendor specific enhancements.
With careful planning, migration to NFSv4.1 (and NFSv4.2 when it becomes generally available) from prior versions can be accomplished without modification to applications or the supporting operational infrastructure, for a wide range of applications; home directories, HPC storage servers, backup jobs and a variety of other applications.
FOOTNOTE: Parts of this blog were originally published in Usenix ;login: February 2012 under the title The Background to NFSv4.1. Used with permission.
Update: Want to learn more about NFS? Check out these SNIA ESF webcasts: