In the first of our “Everything You Wanted To Know About Storage But Were Too Proud To Ask – Part Chartreuse,” we covered the storage basics to break down the entire storage picture and identify the places where most of the confusion falls. It was a very well attended event and I’m happy to report, everyone’s pride stayed intact! We got some great questions from the audience, so as promised, here are our answers to all of them:
Q. What is parity? What is XOR?
A. In RAID, there are generally two kinds of data that are stored: the actual data and the parity data. The actual data is obvious; parity data is information about the actual data that you can use to reconstruct it if something goes wrong.
It’s important to note that this is not simply a copy of A and B, but rather a logical operation that is applied to the data. Commonly for RAID (other than simple mirroring) the method used is called an exclusive or, or XOR for short. The XOR function outputs true only when inputs differ (one is true, the other is false).
There’s a neat feature about XOR, and the reason it’s used by RAID. Calculate the value A XOR B (let’s call it AxB). Here’s an example on a pair of bytes.
A 10011100
B 01101100
A XOR B is AxB 11110000
Store all three values on separate disks. Now, if we lose A or B, we can use the fact that AxB XOR B is equal to A, and AxB XOR A is equal to B. For example, for A;
B 01101100
AxB 11110000
A XOR AxB is A 10011100
We’ve regenerated the A we lost. (If we lose the parity bits, they can just be reconstructed from A and B.)
Q. What is common notation for RAID? I have seen RAID 4+1, and RAID (4,1). In the past, I thought this meant a total of 5 disks, but in your explanation it is only 4 disks.
A. RAID is notated by levels, which is determined by the way in which data is laid out on disk drives (there are always at least two). When attempting to achieve fault tolerance, there is always a trade-off between performance and capacity. Such is life.
There are 4 common RAID levels in use today (there are others, but these are the most common): RAID 0, RAID 1, RAID 5, and RAID 6. As a quick reminder from the webinar (you can see pictures of these in action there):
- RAID 0: Data is striped across the disks without any parity. Very fast, but very unsafe (if you lose one, you lose all)
- RAID 1: Data is mirrored between disks without any parity. Slowest, but you have an exact copy of the data so there is no need to recalculate anything to reconstruct the data.
- RAID 5: Data is striped across multiple disks, and the parity is striped across multiple disks. Often seen as the best compromise: Fast writes and good safety net. Can withstand one disk loss without losing data.
- RAID 6: Data is striped across multiple disks, and two parity bits are stored on all the disks. Same advantages of RAID 5, except now you can lose 2 drives before data loss.
Now, if you have enough disks, it is possible to combine RAID levels. You can, for instance, have four drives that combine mirroring and striping. In this case, you can have two sets of drives that are mirrored to each other, and the data is striped to each of those sets. That would be RAID 1+0, or often called RAID 10. Likewise, you can have two sets of RAID 5 drives, and you could stripe or mirror to each of those sets, and it would be RAID 50 or RAID 51, respectively.
Erasure Coding has a different notation, however. It does not use levels like RAID; instead, EC identifies the number of data bits and the number of parity bits.
So, with EC, you take a file or object and split it into ‘k’ blocks of equal size. Then, you take those k blocks and generate n blocks of the same size, such that any k out of n blocks suffice to reconstruct the original file. This results in a (n,k) notation for EC.
Since RAID is a subset of EC, RAID6 is the equivalent of EC or RAID(n,2) or n data disks and 2 parity disks. RAID(4,1) is RAID5 with 4 data and 1 parity, and so on.
Q. Which RAIDs are classified/referred to as EC? I have often heard people refer to RAID 5/6 as EC. Is this only limited to 5/6?
A. All RAID levels are types of EC. The math is slightly different; traditional RAID uses XOR, and EC uses Galois Fields or polynomial arithmetic.
Q. What’s the advantage of RAID5 over RAID1?
A. As noted above, there is a tradeoff between the amount of capacity that you need in order to stay fault tolerant, and the performance you wish to have in any system.
RAID 1 is a mirrored system, where you have a single block of data being written twice – one to each disk. This is done in parallel, so it doesn’t take any extra time to do the write, but there’s no speed-up either. One advantage, however, is that if a disk fails there is no need to perform any logical calculations to reconstruct data – you already have a copy of the intact data.
RAID 5 is more distributed. That is, blocks of data are written to multiple disks simultaneously, along with a parity block. That is, you are breaking up the writing obligations across multiple disks, as well as sending parity data across multiple disks. This significantly speeds up the write process, but more importantly it also distributes the recovery capabilities as well so that any disk can fail without losing data.
Q. So RAID improves WRITES? I guess because it breaks the data into smaller pieces that can be written in parallel. If this is true, then why will READ not benefit from RAID? Isn’t it that those pieces can be read and re-combined into a larger piece from parallel sources would be faster?
A. RAID and the “striping” of IO can improve writes by reducing serialization by allowing us to write anywhere. But a specific block can only be read from the disk it was written to, and if we’re already reading or writing to that disk and it’s busy – we must wait.
Q. Why is EC better for object stores than RAID?
A. Because there’s more redundancy, EC can be made to operate across unreliable and less responsive links, and at potentially geographic scales.
Q: Can you explain about the “RAID Penalty?” I’ve heard it called “Write Penalty” or “Read before Write penalty.”
A. When updating data that’s already been written to disk, there’s a requirement to recalculate the parity data used by RAID. For example, if we update a single byte in a block, we need to read all the blocks, recalculate the parity, and write back the updated data block and the parity block (twice in the case of dual parity RAID6).
There are some techniques that can be used to improve the performance impact. For example, some systems don’t update blocks in place, but use pointer-based systems and only write new blocks. This technique is used by flash-based SSDs as the write size is often 256KB or larger. This can be done in the drive itself, or by the RAID or storage system software. It is very important to avoid when using Erasure Coding as there are so many data blocks and parity blocks to recalculate and rewrite that it would become prohibitive to do an update.
Q. What is the significance of RAIN? We have not heard much about it.
A.A Redundant Array of Independent Nodes works under the same principles of RAID – that is, each node is treated as a failure domain that must be avoided as a Single Point of Failure (SPOF).Where as RAID maintains an understanding of data placement on individual drives within a node, RAIN maintains an understanding of data placement on nodes (that contain drives) within a storage environment.
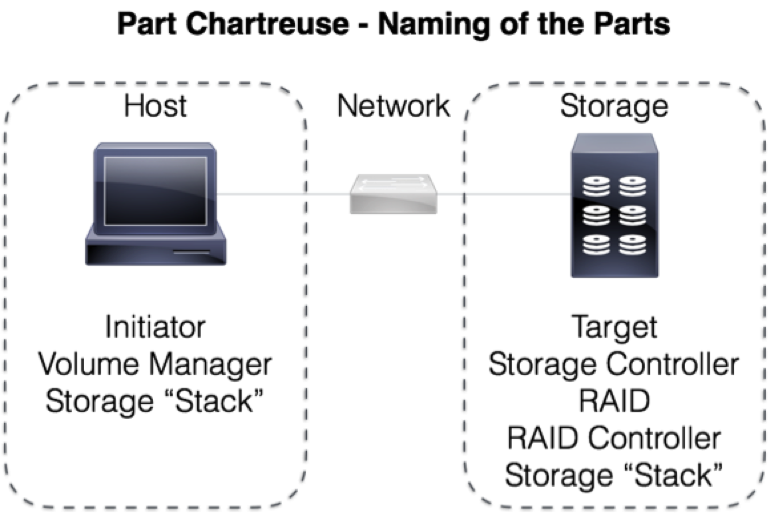
Q. Is host same as node?
A. At its core, a “node” is an endpoint. So, a host can be a node, but so can a storage device at the other end of the wire.
Q. Does it really matter what Erasure Coding (EC) technologies are named or is EC just EC?
A. A. Erasure Coding notation refers to the level of resilience involved. This notation underscores not only the write patterns for storage of data, but also the mechanisms necessary for recovery. What ‘matters’ really will depend upon the level of involvement for those particular tasks.
Q. Is the Volume Manager concept related to Logical Unit Numbering (LUNs)?
A. It can be. A volume manager is an abstraction layer that allows a host operating system to create a Volume out of one or more media locations. These locations can be either logical or physical. A LUN is an aggregation of media on the target/storage side. You can use a Volume Manager to create a single, logical volume out of multiple LUNs, for instance.
A. For additional information on this, you may want to watch our SNIA-ESF webcast, “Life of a Storage Packet (Walk).”
Q. What’s the relationship between disk controller and volume manager?
A. Following on the last question, a disk controller does exactly what it sounds like – it controls disks. A RAID controller, likewise, controls disks and the read/write mechanisms. Some RAID controllers have additional software abstraction capabilities that can act as a volume manager as well.
We hope these answers clear things up a bit more. As you know, our “Everything You Wanted To Know About Storage, But Were Too Proud To Ask” is a series, since this Chartreuse event, we’ve done “Part Mauve – The Architecture Pod” where we explained channel vs. bus, control plane vs. data plane and fabric vs. network. Check it out on-demand and follow us on Twitter @SNIAESF for announcements on upcoming webcasts.
Update: If you missed the live event, it’s now available on-demand. You can also download the webcast slides.