“Software Defined” is a label being used to define advances in network and storage virtualization and promises to greatly improve infrastructure management and accelerate business agility. Network virtualization itself isn’t a new concept and has been around in various forms for some time (think vLANs). But, the commercialization of server virtualization seems to have paved the path to extend virtualization throughout the data center infrastructure, making the data center an IT environment delivering dynamic and even self-deployed services. The networking stack has been getting most of the recent buzz and I’ll focus on that portion of the infrastructure here.
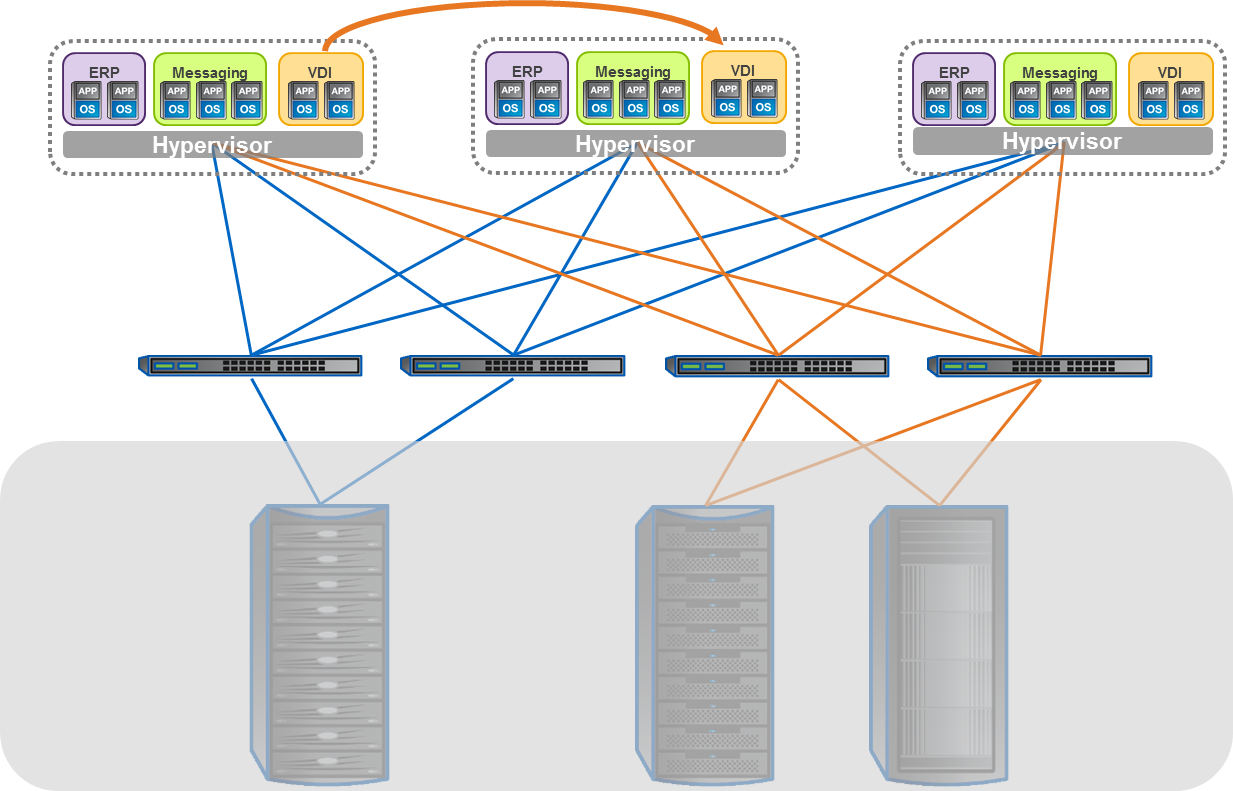 What is driving this trend in data networking? As I mentioned, server virtualization has a lot to do with the new trend. Virtualizing applications makes a lot of things better, and makes some things more complicated. Server virtualization enables you to achieve much higher application density in your data center. Instead of a one-to-one relationship between the application and server, you can host tens of applications on the same physical server. This is great news for data centers that run into space limitations or for businesses looking for greater efficiency out of their existing hardware.
What is driving this trend in data networking? As I mentioned, server virtualization has a lot to do with the new trend. Virtualizing applications makes a lot of things better, and makes some things more complicated. Server virtualization enables you to achieve much higher application density in your data center. Instead of a one-to-one relationship between the application and server, you can host tens of applications on the same physical server. This is great news for data centers that run into space limitations or for businesses looking for greater efficiency out of their existing hardware.
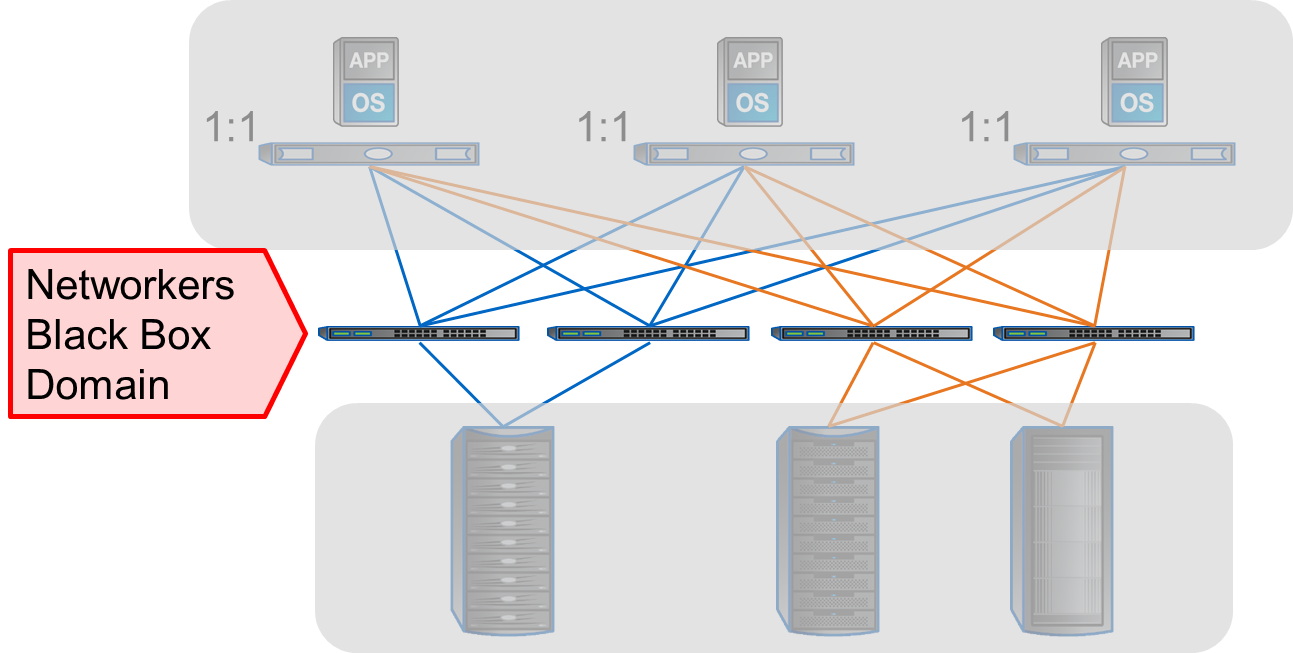 The challenge, however, is that these applications aren’t stationary. They can move from one physical server to another. And this mobility can add complications for the networking guys. Networks must be aware of virtual machines in ways that they don’t have to be aware of physical servers. For network admins of yesteryear, their domain was a black box of “innies” and “outies”. Gone are the days of “set it and forget it” in terms of networking devices. Or is it?
The challenge, however, is that these applications aren’t stationary. They can move from one physical server to another. And this mobility can add complications for the networking guys. Networks must be aware of virtual machines in ways that they don’t have to be aware of physical servers. For network admins of yesteryear, their domain was a black box of “innies” and “outies”. Gone are the days of “set it and forget it” in terms of networking devices. Or is it?
Software defined networks (aka SDN) promise to greatly simplify the network environment. By decoupling the control plane from the data plane, SDN allows administrators to treat a collection of networking devices as a single entity and can then use policies to configure and deploy networking resources more dynamically. Additionally, moving to a software defined infrastructure means that you can move control and management of physical devices to different applications within the infrastructure, which give you flexibility to launch and deploy virtual infrastructures in a more agile way.
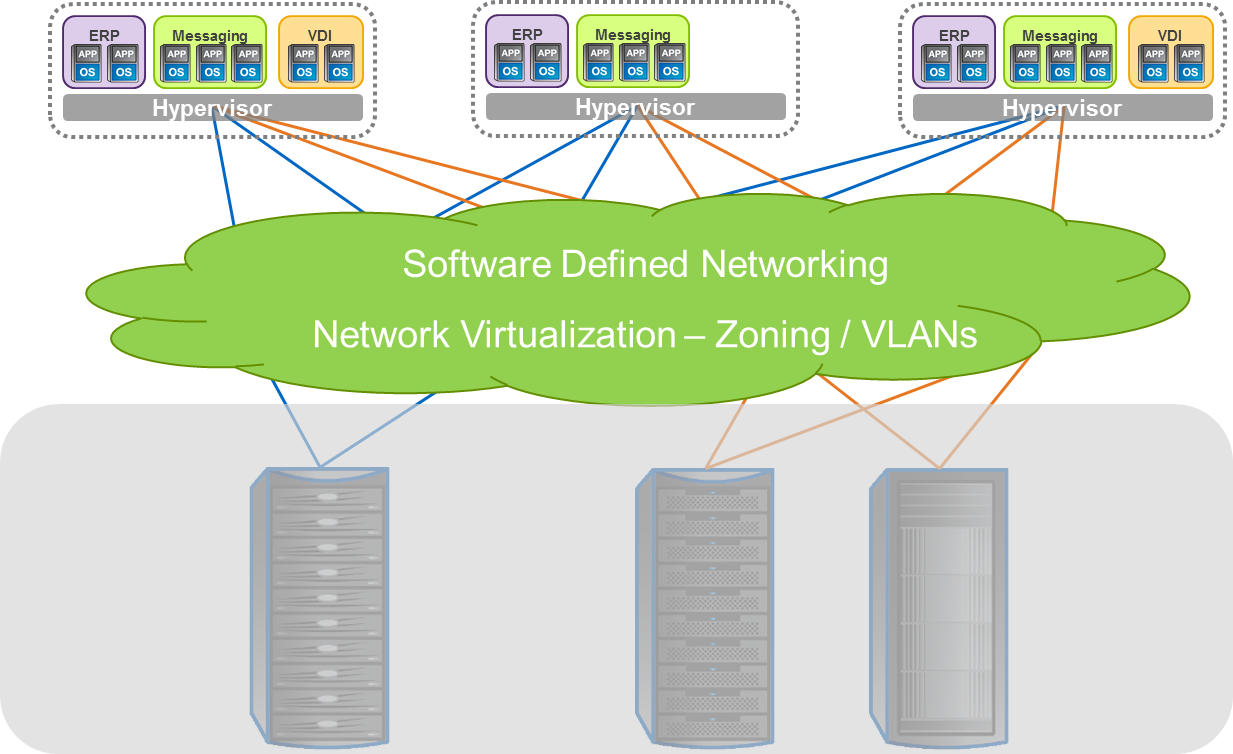 Software defined networks aren’t limited to a specific physical transport. The theory, and I believe implementation, will be universal in concept. However, the more that hardware can be deployed in a consistent manner, the greater flexibility for the enterprise. As server virtualization becomes the norm, servers hosting applications with mixed protocol needs (block and file) will be more common. In this scenario, Ethernet networks offer advantages, especially as software defined networks come to play. Following is a list of some of the benefits of Ethernet in a software defined network environment.
Software defined networks aren’t limited to a specific physical transport. The theory, and I believe implementation, will be universal in concept. However, the more that hardware can be deployed in a consistent manner, the greater flexibility for the enterprise. As server virtualization becomes the norm, servers hosting applications with mixed protocol needs (block and file) will be more common. In this scenario, Ethernet networks offer advantages, especially as software defined networks come to play. Following is a list of some of the benefits of Ethernet in a software defined network environment.
Ubiquitous
Ethernet is a very familiar technology and is present in almost every compute and mobile device in an enterprise. From IP telephony to mobile devices, Ethernet is a networking standard commonly deployed and as a result, is very cost effective. The number of devices and engineering resources focused on Ethernet drives the economics in favor of Ethernet.
Compatibility
Ethernet has been around for so long and has proven to “just work.” Interoperability is really a non-issue and this extends to inter-vendor interoperability. Some other networking technologies require same vendor components throughout the data path. Not the case with Ethernet. With the rare exception, you can mix and match switch and adapter devices within the same infrastructure. Obviously, best practices would suggest that at least a single vendor within the switch infrastructure would simplify the environment with a common set of management tools, features, and support plans. But, that might change with advances in SDN.
Highly Scalable
Ethernet is massively scalable. The use of routing technology allows for broad geographic networks. The recent adoption of IPv6 extends IP addressing way beyond what is conceivable at this point in time. As we enter the “internet of things” period in IT history, we will not lack for network scale. At least, in theory.
Overlay Networks
Overlay Networksallow you to extend L2 networks beyond traditional geographic boundaries. Two proposed standards are under review by the Internet Engineering Task Force (IETF). These include Virtual eXtensible Local Area Networks (VXLAN) from VMware and Network Virtualization using Generic Routing Encapsulation (NVGRE) from Microsoft. Overlay networks combine L2 and L3 technologies to extend the L2 network beyond traditional geographic boundaries, as with hybrid clouds. You can think of overlay networks as essentially a generalization of a vLAN. Unlike with routing, overlay networks permit you to retain visibility and accessibility of your L2 network across larger geographies.
Unified Protocol Access
Ethernet has the ability to support mixed storage protocols, including iSCSI, FCoE, NFS, and CIFS/SMB. Support for mixed or unified environments can be more efficiently deployed using 10 Gigabit Ethernet (10GbE) and Data Center Bridging (required for FCoE traffic) as IP and FCoE traffic can share the same ports. 10GbE simplifies network deployment as the data center can be wired once and protocols can be reconfigured with software, rather than hardware changes.
Virtualization
Ethernet does very well in virtualized environments. IP address can easily be abstracted from physical ports to facilitate port mobility. As a result, networks built on an Ethernet infrastructure leveraging network virtualization can benefit from increased flexibility and uptime as hardware can be serviced or upgraded while applications are online.
Roadmap
For years, Ethernet has increased performance, but the transition from Gigabit Ethernet to 10 Gigabit Ethernet was a slow one. Delays in connector standards complicated matters. But, those days are over and the roadmap remains robust and product advances are accelerating. We are starting to see 40GbE devices on the market today, and will see 100GbE devices in the near future. As more and more data traffic is consolidated onto a shared infrastructure, these performance increases will provide the headroom for more efficient infrastructure deployments.
Some of the benefits listed above can be found with other networking technologies. But, Ethernet technology offers a unique combination of technology and economic value across a broad ecosystem of vendors that make it an ideal infrastructure for next generation data centers. And as these data centers are designed more and more around application services, software will be the lead conversation. To enable the vision of a software defined infrastructure, there is no better network technology than Ethernet.