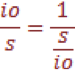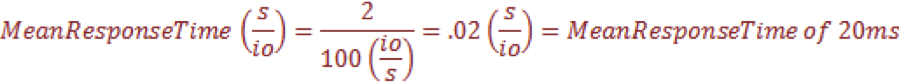Our recent Ethernet Storage Forum Webcast, “Storage Performance Benchmarking: Part 2,” has already been viewed by more than 500 people. If you haven’t seen it yet, it’s now available on –demand. Our expert presenters, Ken Cantrell and Mark Rogov did a great job fielding questions during the live event, but of course there wasn’t time to get to them all. So, as promised here are their answers to all of them. If you have additional questions or thoughts, please comment on this blog and we’ll get back to you as soon as we can.
Q: “As an example, am I right to presume workloads are generated by VMs”
A: Ken: It is probably a good idea at this point to define a workload, since we continue to use the term. At a very high level, think of a workload as the mix of operations issued by an application related to the accessing of data. In our case, data stored or made available by a storage solution. With that in mind, absolutely, workloads can be generated by VMs. But they don’t have to be. In other words, “it depends.”
For example, consider these 3 cases:
1) If your SUT (solution under test) was just a simple laptop with no hypervisor and a traditional OS, then there would be no VM in the mix. Your workload would be generated by the application you were measuring (whether that was a simple file copy or something complex like a local database installation).
2) Your SUT is composed of a physical client (like the laptop above) attached to a machine with a hypervisor installed on it and a local guest OS installation that is capable of exporting NFS or SMB shares. The laptop sends I/O via Ethernet to the guest OS. In this example, there is a VM, but it is acting as the storage system, not the workload generator.
3) Now reverse the I/O of example 2. Have the laptop export an SMB share and have the guest OS issue I/Os to that share. Now you finally have VMs generating workloads.
A: Mark: If one examines the solution under test (SUT), and considers the general data flow, then the workload is generated by the clients/hosts layer. Yes, we indicated that the clients/hosts can be VMs, but they also could be physical systems, and, in the case of a SUT consisting of just one laptop, the workload is generated by the application.
Q: Are you going to get around to file performance benchmarking? This infrastructure stuff is not new to me. I have done block all my life, I am interested in stuff about file.
A: Ken: That’s the plan. We are still working out the exact sequence, timing and content for future presentations, but had a dedicated section on both block and file on the original roadmap. If you have specific topics within “file” that you’d like covered, respond in the comments. No promises to cover them, but knowing the desires of the audience is always a good thing.
Keep in mind the intention of the webcast series – lay a strong, but simple foundation, for storage performance fundamentals and then build on that foundation.
A: Mark: The main intent of the series is to lay down basic performance principles first, then build on them to go to more complex topics. Both Ken and I refer to ourselves as “File Heads” and we can’t wait to concentrate on just file, but it would only make sense given that the infrastructure foundations are firm and understood by our audience.
Q: Why doesn’t SPEC SFS have performance testing for such failure models?
A: Ken: Brighttalk provided this comment in isolation, so it isn’t entirely clear which failure models you’re asking for. I’m assuming you mean a failure like a drive or controller failure. With that assumption, that said, the SFS subcommittee welcomes publications that illustrate a failure condition. SPEC SFS 2014 provides an excellent opportunity for someone to publish once in a non-failure scenario and then again in a failure condition of some sort – as long as that failure condition doesn’t violate any of the run rules regarding stable storage and the failure condition doesn’t generate user visible errors.
Note that SPEC SFS 2014 doesn’t mandate any demonstration of failure scenarios. We’ve discussed this in the past, but it has never been a priority for those that participate in SPEC (which is open to all – see http://www.spec.org for instructions on how to join the SPEC Open Systems Group).
Q: Why is write cache turned off for enterprise drives?
A: Ken: I knew this question was coming. 🙂 This is related to “stable storage” – the guarantee from your storage provider that data they say is safely stored on disk is actually stored on disk. I should clarify that the comment is a little dated and refers to caches designed around volatile memory; this wouldn’t apply to a hybrid SSD/spinning media drive that used the SSD to cache/stage data, since SSDs are non-volatile.
Consider the failure scenario where the enterprise drive has write caching enabled and then experiences a power failure. In most every system sold, the storage controller treats drives pretty much as black boxes – they tell the drive to read or write data at a certain location and expect the drive to do as told. So, when the drive says “yup, I got that data, you’re good!” the storage solution trusts the drive and, when it doesn’t need it in memory any longer, throws it away (that data is safely stored on disk, so this is ok). If the drive chose to cache that information in volatile memory, and loses power, the information is gone.
Midrange and enterprise storage vendors often (I think I can say generally) provide some sort of battery backup in case of power failures. These battery units keep power to at least some of the drives – but remember that drives (especially spinning ones) suck down a lot of power, and often the implementation chooses to keep power only to certain drives that the storage controller uses to flush its own volatile memory structures to.
A quick Internet search shows some specific comments on this topic:
From Seagate (http://knowledge.seagate.com/articles/en_US/FAQ/187751en):
Windows 2000 Professional / Server, Windows XP Home / Professional, Windows Vista and Windows 7 have a nifty little feature called write caching buried within the depths of property tabs. Normally, this type of feature is used with SCSI drives in server applications to provide greater data integrity.
When drives employ write-back cache, any interruption of power to the drive or system may cause lost or corrupted data because the drive does not have time to write the cached data to the disk before the power is lost. However, when write cache is turned off, drive performance slows down.
From Microsoft (https://support.microsoft.com/en-us/kb/259716):
…In addition, enabling disk write caching may increase operating system performance. This article describes how to enable or disable disk write caching…
NOTE: Enabling write caching generates the following warning. This is normal:
By enabling write caching, file system corruption and/or data loss could occur if the machine experiences a power, device or system failure and cannot be shutdown properly.
Q: What’s the difference between CPU and ASIC? When to use which word?
A: Ken: Unfortunately, the SNIA dictionary doesn’t define either term. At the easiest level, both are acronyms. CPU = central processing unit, and ASIC = application specific integrated circuit. At the next level, think of a CPU as general purpose processing element and an ASIC as a custom designed microchip designed for a special application or purpose. Once created, ASICs are non-programmable – they do something very specific (and hopefully very well and very quickly/efficiently). A CPU can run your bitcoin mining program overnight, wake you to Spotify in the morning, let you use your favorite word processor in between games of Plants vs. Zombies, and still let you watch Hulu before you head off to bed.
An ASIP (Application Specific Instruction-Set Processor) bridges the gap between a general purpose processor (CPU) and the highly specific, targeted design of an ASIC. An ASIP will have a much reduced instruction set and a more targeted design towards a specific application (say, digital signal processing), but still allow the execution of a specific instruction set given to it.
Q: Can you mention tools to identify the bottlenecks?
A: Ken: We are trying very hard, particularly in the webcasts themselves, to stay vendor neutral. I don’t mind violating that though here in the Q&A a little bit.
From an open source standpoint, there are a number of tools. One of the more popular now is to use something like Graphana as a front-end to Graphite, and use that to monitor a set of open source (or privately designed) sensors, including sensors from OPM below, that you place throughout your environment.
Here are a few other open-source benchmarking and performance tools, and what aspect of performance to which they apply. Please note that this is not a comprehensive list, nor is this a recommendation for their use. We are providing the link as a convenience, not an endorsement. [http://www.opensourcetesting.org/performance.php]
Still free, but NetApp-centric, is OnCommand Performance Manager (OPM), specifically OPM v2.0 and later. In addition to providing performance metrics for your NetApp storage array, OPM offers up the concept of a “bully” and “victim” scenario – it specifically watches for components that are performing poorly (the “victims”) and helps identify which other components are causing that poor behavior (the “bullies”). My team helps develop OPM.
Not free, and not NetApp centric, but a NetApp product, is OnCommand Insight (OCI). This is a premier product for looking at the performance of the components across your datacenter.
A: Mark: I didn’t want to break the vouch to neutrality. 🙂 EMC has a number of tools as well, vRealize suite, ViPR SRM, Unisphere, plus platform specific tools… However, it has been my experience that the most important tool a performance expert has is still the critical mind. One observes the problem, and then walks the entire set of the SUT layers looking for incongruences. Too often, the perceived bottleneck is not the problem, but a manifestation of a problem somewhere else. For example, as we pointed in the “MiB/s section” of this webcast, the network layer was a bottleneck due to the badly configured OS multipath drivers. Deciphering cause from reason requires several things: a good understanding of the SUT and its layers; a critical mind to analyze problem conditions; and a large dose of curiosity. The latter one a personal trait that drives us to question “what if I change this to that?” Asking questions while troubleshooting is, IMHO, a cornerstone requirement and inherently, a very human trait. My personal view is that tools are just tools, and they require a human hand to operate and a human mind to analyze the results.
Q: Did All flash arrays almost eliminate bottleneck..,at least the Storage controller bottleneck can be eliminated if enterprise can afford all flash arrays?
A: Ken: Actually, almost exactly the opposite. Spinning drives are (now, at least) relatively slow. Over the past 10 years the drives have gotten much bigger, although HDD drive speeds haven’t really changed all that much,. Because of this, what I’ve observed is that the IOPS/GB ratio for HDD has, if anything, been getting worse* and the most common bottleneck for an HDD-based customer turns out to be the speed of their drives.
Now consider what happens when a customer moves to SSDs. The SSDs that are sold (and folks can afford) are generally much smaller than the HDDs they are used to, so customers buy as many of them as they can in order to meet their capacity requirements. And the SSDs are, one-for-one, much faster. So what happens? High drive counts + really fast drives = the drives aren’t your bottleneck anymore. Instead, the bottleneck shifts upstream … in a well architected solution, generally to the storage controller or clients.
*For those that know the terms, we could have a long discussion about working set sizes over the years, how fast data ages, tiered storage and such, and the effect that these have on observed iops/GB … but I think we could agree that since HDD speeds aren’t increasing, the iops/GB ratio isn’t generally getting better.
Q: Can I download this slides?
A: Ken: Absolutely. Here are the links to Part 1 of our series:
PPT and PDF: http://www.snia.org/forums/esf/knowledge/webcasts (look for “Storage Performance Benchmarking: Introduction and Fundamentals (July 2015)”)
Presentation Recording: https://www.brighttalk.com/webcast/663/164323
Q&A Blog: https://sniansfblog.org/?p=447
Here are the links to Part 2:
PPT and PDF: http://www.snia.org/forums/esf/knowledge/webcasts (look for “Storage Performance Benchmarking: Part 2 (October 2015)”)
Presentation Recording: https://www.brighttalk.com/webcast/663/164335
Q&A Blog: That’s what you’re reading now. 🙂
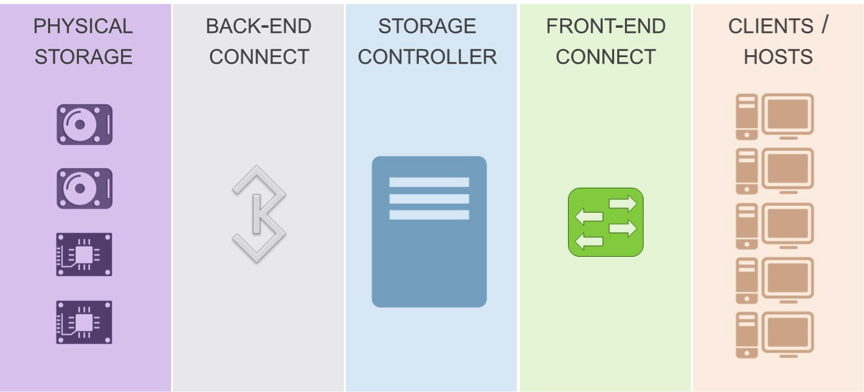
Q: Storage controller, is a compute node, right? And for hyper converged systems, storage controller and compute nodes are the same, right?
A: Mark: Most certainly, a Storage Controller can be a compute node, but in our webcast it is not. The term “compute node” is typically interpreted to be a part of the client/hosts layer. A compute node computes for the application, and such application is generating the workload (please see the question above about where workload is initiated).
A good example of the compute node would be a system that renders cartoons, or geodesic fields. As such compute node computes something (application does the work), and stores the results onto the storage controller.
However, in the case of hyper-converged infrastructure, the storage controller is often virtualized among the client hosts, making every compute node a part of a larger storage controller.
Q: Are the performance numbers that vendors publish typically front-end?
A: Mark: I don’t want to generalize published numbers as being one way or another. I recommend reading every publication for specific details. Vendors publish numbers to cover use cases, and each use case may come with its own set of expected measurement points and metrics. Ken and I talked about how metrics matter in the first Storage Performance Benchmarking webcast. 🙂
Q: “We did an R&D PoC using 32 flash 400GB elements attached on DIMM slots (not through SAS controller, not a direct PCIe attach) and seven 40Gbps cards. We were able to pump 5.5M 4KB-IOPS resulting in 30GB/s (240Gbps) of traffic on the front-end connect. When do you expect the front-end connect be the bottleneck for more standard environment?”
A: Ken: Woot! That sounds like a lot of fun. If you’re in the Raleigh, NC area and can talk about that not under NDA, we should have lunch. I’d like to hear more.
I have a suspicion that this answer won’t satisfy you, because it isn’t going to be as empirical as your example. The problem in answering with raw numbers is that there isn’t a standard configuration for a SUT. An enterprise class storage array with a mix of 40GbE and 32GB FC connections (with traffic over both) will look very different than someone using their old Windows XP box with a single 100Mbit to share out an SMB share, and both will look different than someone accessing their photos on their favorite cloud provider. So, I’ll answer the question by saying that I expect the front-end connect to be the bottleneck anytime the rest of the components in the SUT are capable of hitting your performance metrics (whether that be in terms of response time, IOPS, or data rates), and the front-end connect isn’t.
THAT said, you’d be astounded how often, even today, that MTU mismatches result in terrible front-end performance (and functionality).
Q: “Example of cache in front end connection?”
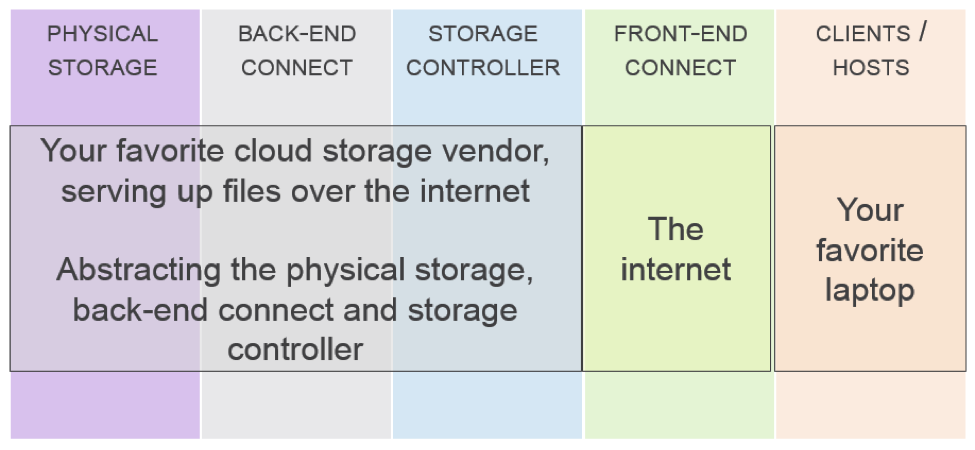
A: Ken: I’ll cheat and note that SUTs can be a lot more complicated than we showed. For example, our picture looked like this:
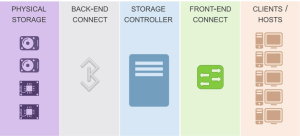
Consider a SUT then where you have:
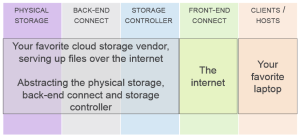
At one level, “the internet” is just a big black box acting as our front-end connect. But if we zoom in on it, perhaps we find that somewhere along the line there’s a caching server. Then we have an easy answer to where you find cache in the front-end connect.
In the much simpler model that you’ll find in many enterprise data environments though, you’ll find that the front-end connect consists of some relatively short length cables and a set of switches – either SAN or NAS switches. And in those environments, you won’t find a lot of cache. You will find memory, but you’ll find it used for buffering more than for caching.
We tried to minimize this in the presentation since there’s not a universally agreed upon distinction between these two terms. I think of a buffer (in this context) primarily as memory set aside to hold data very briefly, after which it is consumed and removed from the buffer. I think of cache, on the other hand, as a storage medium that holds data specifically to speed up data access (storage or retrieval). Data held in a cache can be held for a very long time, and not all data in a cache may ever be consumed/used.
Q: Even SSDs suck at random write but they are good for random read, is there that much difference?
A: Ken: Yes. The data we pulled for drive speeds was real data. And keep in mind that “sucks” is pretty relative here. Enterprise SSDs still tend to be at least 4x faster than spinning media. And, very importantly, their performance is much more consistent and deterministic since seek time is irrelevant with an SSD. New NVRAM technologies, like 3D XPoint, promise to dramatically improve write performance.
DRAM is volatile though so replacing HDDs with that wouldn’t really work, right? But if capacity requirements are high, we cannot replace disks with the cache, right?
A: Mark: Cache should never replace capacity. Cache is temporary storage, and requires by design to move its data to a permanent storage location. The size of cache should be matched to the size of the data that application uses, so called “working area”. For example, if an application writes to a 4GB file (think VMware vmdk), then for best performance the entire 4GB should fit into cache. However, capacity requirements for a VMware datastore can be as high as several TB. If the application (ESX server) is running many VMs, perhaps only the performance few need to fit into cache, while all other VMs would use cache for sub-portions of their vmdks.
A: Ken: You’re right, not permanently. As Mark points out, it isn’t to permanently replace the slower storage with cache necessarily, just supplement it enough that the working set fits in.
Q: How can we make client do less IO? Will it make sense?
A: Mark: A client does less IO by using larger IO size, for example. A classic use case is read- and write-sizes within NFS protocol. It is possible to increase read- and write-size of the NFS protocol from the NFS client mount options side. By default, some Linux environments use 32KB for reads and writes. And reading a 1GB file takes 32768 32KB IOs. If the read size is increased to 1GB, then it takes only 1024 IOs – a 32x reduction!
A: Ken: Other options involve app re-writes (yes, sometimes these ARE possible) and OS upgrades. Perhaps in the “app-rewrite” category, or maybe a new category, I’ve also worked with developers to rewrite their DB queries to be much less disk intensive, for example.
Q: Can you elaborate on some of the client level cache types other than file system or OS?
A: Mark: Other than file system and OS? Hmm… Let’s see: PCI-based cards that cache block-device level cache, e.g. EMC VFCache, SanDisk Fusion-IO, NetApp Flash Cache. Native network protocols (CIFS and NFS) caches. Local database caching, e.g., SafePeak, TimesTen, Windows Azure Caching.
Q: Please add more sessions, which goes into every detail
A: Mark: Absolutely! We will! Promise! We’re shooting for Part 3 in Q1 2016.
Update: This webcast is part of a series on storage performance benchmarking. Check out the others:
 Nearly 1,000 people have watched our most recent SNIA ESF webcast, Storage Performance Benchmarking: Workloads. We hope you didn’t miss this 5th and final installment of the now famous Storage Performance Benchmarking webcast series where our experts, Mark Rogov and Chris Coniff, explained how to measure and optimize storage performance of workloads. If you haven’t seen it, it’s available on-demand. The live audience had many great questions. Here are answers to them all.
Nearly 1,000 people have watched our most recent SNIA ESF webcast, Storage Performance Benchmarking: Workloads. We hope you didn’t miss this 5th and final installment of the now famous Storage Performance Benchmarking webcast series where our experts, Mark Rogov and Chris Coniff, explained how to measure and optimize storage performance of workloads. If you haven’t seen it, it’s available on-demand. The live audience had many great questions. Here are answers to them all.